该文档主要针对运维人员不在线紧急处理系统内的问题,对服务器及服务常见的问题以及每台服务器上部署的服务进行梳理,以便快速处理解决问题。
硬盘容量满
1.清理
硬盘满了这个问题目前只能通过清理虚拟机内的文件,然后释放空间。紧急处理该问题比较好的删除方法是删除容器多余的镜像。
对于 docker 服务器,可以使用如下命令清理未被使用的镜像:
docker image prune -a
备注:在每次服务容器更新后,之前的镜像会变成未被使用的镜像(无 tag 镜像),多了以后会把存储空间打满,可以通过该方法清理
k3s 清理镜像:k3s crictl rmi --prune
2.释放空间
清理完毕后需要在虚拟机内执行命令:fstrim -av 来释放空间
备注:如果是宿主机空间满了无法启动虚拟机,可以优先清理掉:/data/iso/的镜像文件,先把虚拟机启动起来再清理存储空间
3.虚拟机扩容
1.创建虚拟硬盘
qemu-img create -f qcow2 硬盘名称.qcow2 200G
2.添加硬盘至虚拟机
virsh attach-disk 虚拟机 /kvm/硬盘名称.qcow2 vdb --cache=none --subdriver=qcow2
3.远程连接到虚拟机,将新加的硬盘扩容
pvcreate /dev/vdb
vgextend ubuntu-vg /dev/vdb #如果有问题执行vgdisplay看看 vg 的名称
lvextend -l +100%free /dev/ubuntu-vg/ubuntu-lv #如果有问题执行lvdisplay 看看 lv 的名称
4.刷新分区容量
如果是 xfs 系统:xfs_growfs /dev/mapper/ubuntu--vg-ubuntu--lv
如果是 ext4 系统:resize2fs /dev/mapper/ubuntu--vg-ubuntu--lvkvm 虚拟机挂掉
kvm 虚拟机在特殊情况下例如硬盘容量满、宿主机内存 cpu 占用异常会出现挂掉的情况,通常只需要通过virsh resume 虚拟机 来重新启动虚拟机。
通过virsh list --all 查看所有虚拟机
nvidia 掉驱动问题
在有时候显卡服务器重启后,会出现nvidia-smi 命令无法正常输出显卡的问题(服务也无法调用显卡),可以通过/root 目录下的NVIDIA-Linux-x86_64-550.78.run 运行重新安装显卡驱动。(安装一直点击下一步就行)
中间件异常
中间件异常一般分两种,一是存储服务异常,二是部署服务的k3s服务出现异常
ceph 故障
ceph 是公司使用的分布式高可用存储服务,目前所有中间件的数据目录都是挂载该存储,如果发现如下异常有可能是 ceph 本身出现了问题:所有中间件都有异常,一般是无法连接,会超时,但没有明显的报错,并且服务运行状态是正常的。
此时可以远程连接到任意一台 ceph 服务器,例如192.168.2.217,执行如下命令:ceph -s,如health字段并且HEALTH_OK那就是有故障,一般常见的问题只有两种: 1.ceph 存储空间满
2.ceph 节点挂掉太多
ceph 存储空间满
如果是 ceph 空间满了,临时紧急的解决办法有两个
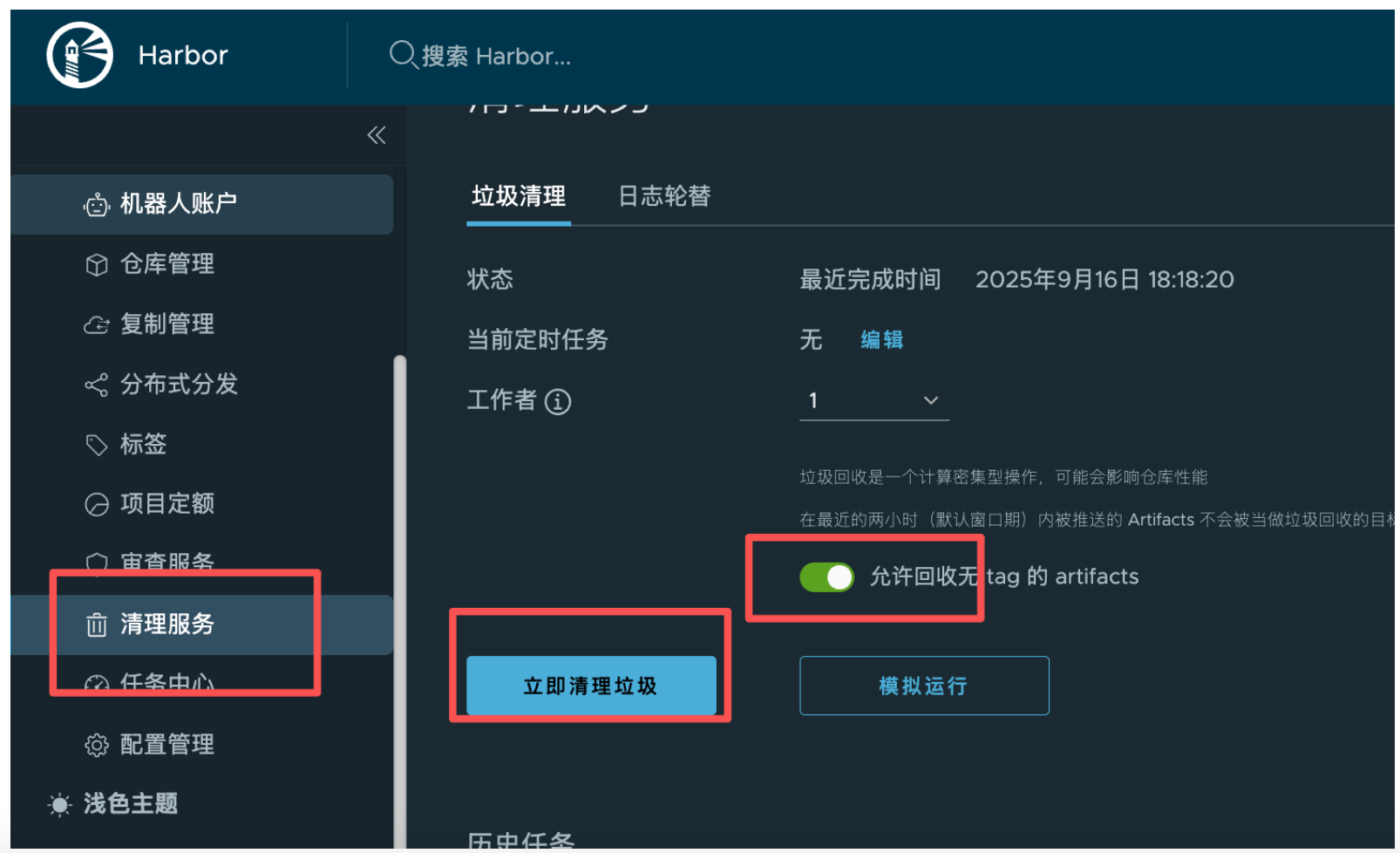
1.清理 harbor 镜像
访问https://harbor.zhxx.site/,进入清理服务菜单,选择允许回收无tag 的 artifacts。(用户名密码请询问运维人员)
2.清理mysql 测试备份 sql
远程连接到 192.168.2.217 服务器,进入目录:/mnt/volumes/csi/csi-vol-97d2a76d-466b-463f-b71b-98fa1389125f/357f4040-a2a2-4b9d-8cc0-014e895085e8/mysql ,执行删除命令
这里的文件夹备份了近 7 天的 sql备份文件,在空间满的情况下可以选择删除一些,例如删除五天前的
find . -type f -name "*.sql" -mtime +5 -exec rm -v {} \;但是为了防止误删,最好先执行命令查看一下有哪些文件会被删除:
find . -type f -name "*.sql" -mtime +5 -ls # 使用 -ls 查看详细信息ceph节点挂掉
ceph作为高可用存储服务,目前在内网环境下一共有四个节点分别是
ceph1:192.168.2.217
ceph2:192.168.2.218
ceph3:192.168.2.226
ceph4:192.168.2.237 ceph只能允许有一个节点的容错,一旦挂掉两个节点及以上,整个存储将无法正常提供服务。当远程连接到任意节点使用ceph -s 超时的时候,这个大概率是ceph挂掉的节点过多,已无法查看ceph任何状态,在宿主机通过virsh start 虚拟机即可。
启动所有节点一般几分钟会自动恢复,除非严重故障,否则无需人为干预处理。
k3s异常
k3s无法连接
还有一种情况是 ceph 都是正常的,然后中间件无法连接。此时一般是k3s本身服务问题,在内网里面k3s有三台主机服务,分别为:node1:192.168.2.211、node2:192.168.2.212、node3:192.168.2.213。远程连接到任意一台主机例如node1,执行命令kubectl get node,正常情况下会返回如下信息:
[root@node1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane,master 657d v1.28.4-rc1+k3s1
node2 Ready control-plane,master 665d v1.28.4-rc1+k3s1
node3 Ready control-plane,master 633d v1.28.4-rc1+k3s1如果是异常的话,一般会返回超时,就是命令执行一直卡着不动,直至超时,这种情况肯定是节点至少挂掉了两台,因为本身是高可用服务,挂掉一台不会影响使用。解决办法是查看node1、node2、node3是否有挂掉的,如果有无法远程的,则启动或重启改服务器,k3s服务本身是自启动的,绝大部分情况不需要人为干预,只需要保证服务器运行正常。
中间件异常
如果确认k3s节点是正常的,可以通过kubectl get pod -A |grep 服务名 查看服务是否正常运行,这里以gitlab为例子:

如果服务状态和图中不一致,例如不是1/1 或者不是 Runing则证明服务本身启动有问题或者正在启动,绝大部分情况下可以通过重启容器来解决问题(如果不是重启能解决的问题这里深究会较为复杂,不再一一展开),重启命令为:
kubectl delete pod <pod名称> -n <名称空间>如果都无法解决大概率是服务启动有异常,可以尝试通过查看日志来排查问题
kubectl logs pod <pod名称> -n <名称空间> #-f参数可以实时查看harbor/gitlab注意
这里内网的gitlab和harbor都是连接的postgresql来作为数据库的,如果本身服务没找到问题,可以先查看postgresql是否正常运行。如果确认k3s正常又没找到其他问题,那么环境内99%的问题都是因为数据库没连上。
验证postgresql是否正常:
方法1:
查看服务是否正常运行,如非正常运行,尝试重启
[root@node1 ~]# kubectl get pod -n devops |grep postgresql
postgresql-5cb8cdf544-frxsr 1/1 Running 1 (26h ago) 26h状态为:1/1 Running 则为正常
如果状态为:0/1 Running 一般是正在启动
如果状态为:0/1 非 running 则有问题
方法2:
通过客户端连接测试,ip端口为:192.168.2.220:5432,用户名密码请询问运维人员。
如果有问题可以优先使用重启来尝试解决
kubectl delete pod <容器名> -n devops 服务器/服务重启
服务偶发性自启动失败的情况
正常情况下服务器重启虚拟机以及服务都是会自动启动的,但目前有些服务由于挂载延迟性或本身非docker等问题,有时候重启会出现没有自动启动或者自动启动失败的情况,需要人为启动,这里把所有在服务器重启时有可能需要人工干预的服务全部记录下来:
预演环境
如果服务器全部重启,有时候预演环境因为启动速度略快于中间件会出现服务启动有问题的情况,docker 本身不像k3s 会检测健康状态然后重新启动容器,所以有时候需要手动处理,如果服务器重启后预演部分服务不太正常,可以远程连接服务器:192.168.2.241执行命令:cd /app/backend && bash start_docker_all.sh。另外由于 nginx 是二进制部署的,有时候会出现 nginx 启动异常的情况,也需手动进行启动:nginx
注意 1:测试环境不会出现此类问题,因为测试环境目前已全部由k3s 服务启动
注意 2:预演环境的mysql、tdengine、redis 是独立的,部署在预演服务器上,以 docker 方式部署,部署和数据路径在/app/middle-components/mysql、tdengine、redis
测试环境
目前测试环境采用k3s 方式部署,如果k3s 服务重启,所有容器服务都会被重新创建(这一点不像 docker 在非人为情况下 docker 不会销毁容器而是可以直接启动),所以这里常有个问题是有时候在 服务器上通过kubectl get pod 命令发现所有服务的STATUS 字段都是ImagePullBackOff 状态。
例如 :
[root@node1 ~]# kubectl get pod -A|grep ImagePullBackOff
cattle-fleet-system fleet-agent-8486ff854d-kmvrl 0/1 ImagePullBackOff 0 24d原因:因为每次创建容器都会去向 harbor 确认当前镜像是否为最新镜像,如果不是则会拉取最新,如果是,则使用本地镜像
解决办法:
远程进入k3s 服务器192.168.2.211,执行如下命令确认 harbor 是否正常运行
[root@node1 ~]# kubectl get pod -n devops |grep harbor
harbor-core-d9fd456f9-p4brb 1/1 Running 11 (26h ago) 4d21h
harbor-jobservice-85555864bb-vb6vq 1/1 Running 11 (26h ago) 4d21h
harbor-portal-67d7b5459b-8spcm 1/1 Running 0 4d21h
harbor-registry-76fc6cdff6-bg7d4 2/2 Running 0 4d21h
harbor-trivy-0 1/1 Running 0 4d21h如果状态非Running或运行非1/1、2/2,则需等待harbor启动完成,或者通过:
kubectl delete pod harbor-core-d9fd456f9-p4brb -n devops 手动重启容器
这里 kubectl delete pod -n devops 是固定参数,然后第一个字段是容器名。
jenkins 更新问题
如果发现 jenkins 打包后服务未正常更新或者更新未生效可以按以下思路排查:
1.查看最新构建 git 提交记录是否对的上(非唯一标准,有时候 jenkins 显示有异常,绝大部分时候是正常的)
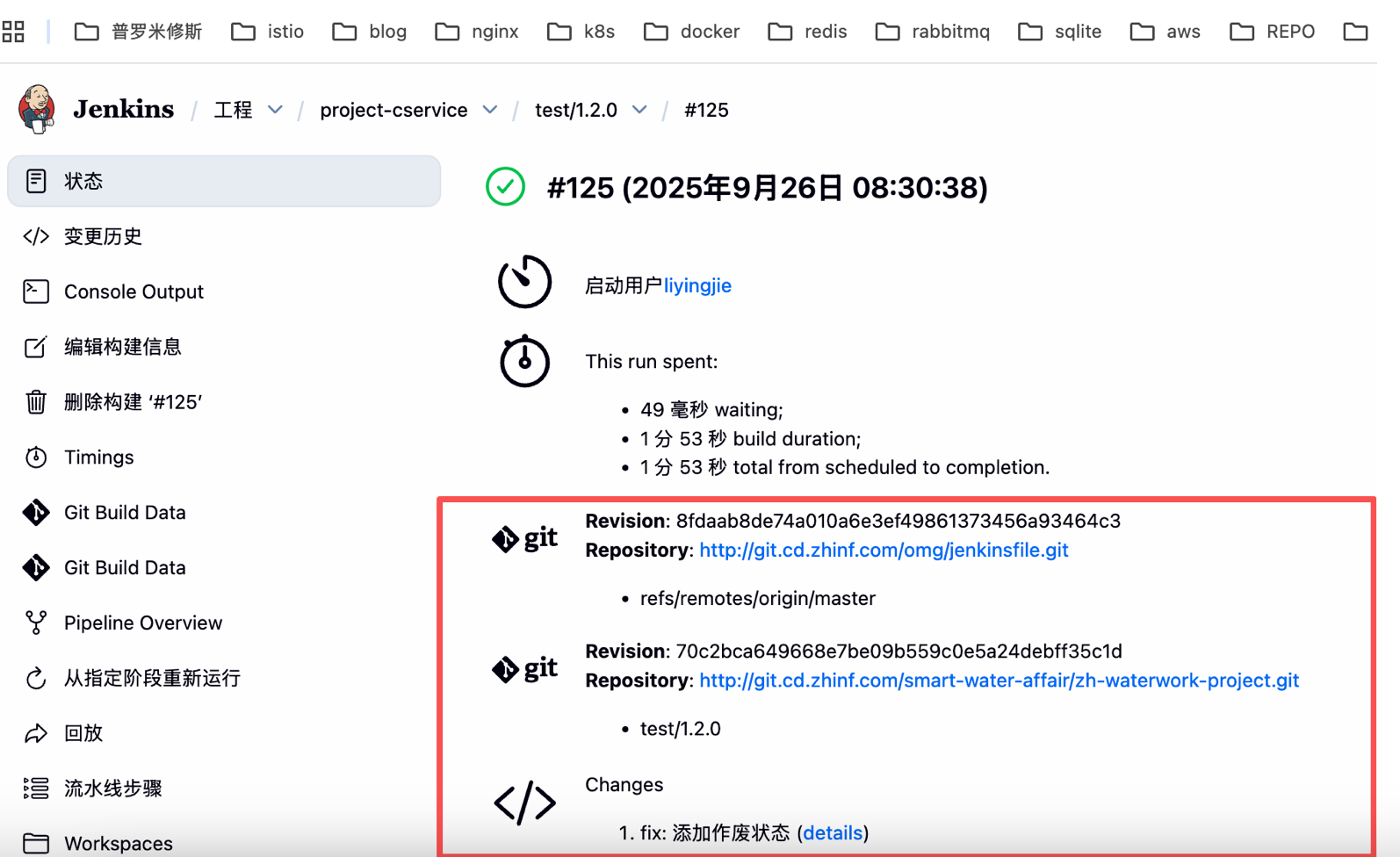
2.查看步骤是否存在异常

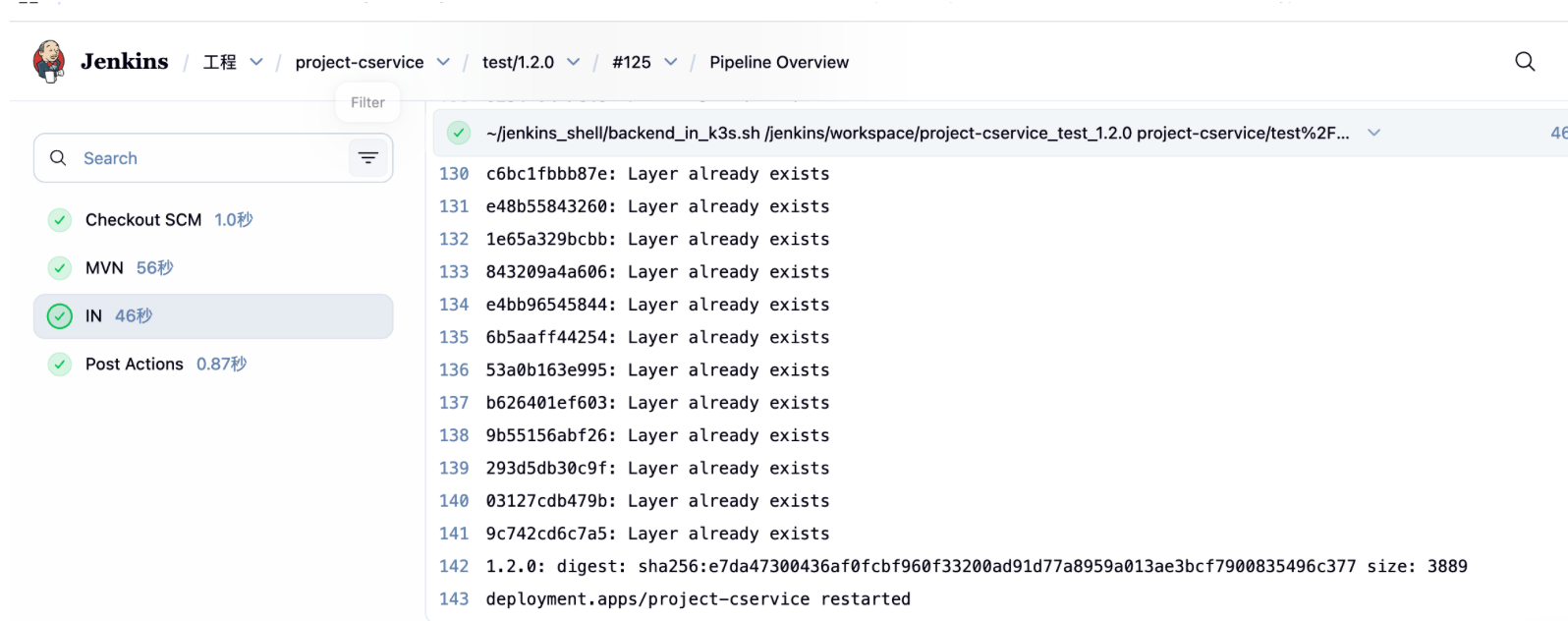
3.查看构建日志,尤其是 IN 阶段
IN 阶段步骤较多,有时候会出现异常但未返回异常,会造成更新未生效,可以通过日志查看排错
4.删除 jenkins 本地 maven 缓存
如果上面的都没问题也确认更新后容器重启了,可以删除jenkins 本地 maven 缓存试试,位于 192.168.2.236 服务器的/jenkins/.m2/repository/目录。