配置文件架构:
前端部署文件:/app/frontend/
后端部署文件:/app/backend/
前端配置文件:/app/frontend/conf
运维服务:/app/devops
运维脚本:/app/devops/shell
中间件服务: /app/components/ 备注: 有些老的部署项目将中间件部署在/app 和/zhxx下面
内网服务器架构:
测试环境服务器:192.168.2.242,底层为k3s,部署前后端服务,代码更新通过 jenkins构建实现。中间件除 xxljob全部连接 192.168.2.220(k3s组件集群)
预演环境服务器:192.168.2.243, 底层为k3s,部署前后端服务,代码更新通过 jenkins构建实现。其中中间件独立部署了:mysql、redis、tdengine、xxljob,其他中间件均全部连接 192.168.2.220(k3s组件集群)
k3s组件集群:192.168.2.220,其中包含三台服务器主机分别为:2.211/2.212/2.213,部署目前环境内所有中间件以及开发相关组件
其他服务器: docker 服务器、本地生产服务器、jenkins 服务器、gpu 服务器、存储服务器
生产服务器: 目前生产服务器前端都采用直接打包的形式部署,后端为 docker,部署路径不变,正常情况下部署文件都位于:/app/下面,有些老的部署项目可能存在/zhxx下面
项目部署架构: 目前测试环境所有项目以由 docker 部署切换为k3s,但底层原理仍未变,均为通过 docker 镜像来进行部署更新。生产环境则目前以 docker 部署为主,前端非 docker 部署。
服务更新及管理:服务部署除生产需要人为更新以外,测试预演均通过jenkins 进行构建打包。服务管理通过 rancher 来进行管理,以及查看服务日志和状态。
日志:这里考虑到有查看历史日志的需求,尤其是生产环境,但反馈 elk 并不好用,考虑后续都采用 loki 来进行日志管理,使用 grafana 来展示。
新框架规范
1.健康监测接口
所有后端服务都需要暴露:/actuator/health 接口,以实现服务状态监测。在测试与预演环境,如果部署的后端服务没有该接口或存在异常,服务会自动重启,直至接口监测正常。
2.nacos
所有后端服务均需要接入 nacos 并通过 nacos 来读取配置,测试、开发、预演均连接:http://nacos.cd.zhinf.com:8848 ,通过名称空间来区分环境。
bootstrap 配置参考如下:
spring:
cloud:
nacos:
discovery:
#服务发现配置,将会默认读取环境变量中的配置数据,如果不到数据,默认关闭
enabled: ${NACOS_DISCOVERY_ENABLE:false}
namespace: ${NACOS_DISCOVERY_NAMESPACE}
server-addr: ${NACOS_DISCOVERY_SERVERADDR}
group: ${NACOS_DISCOVERY_GROUP}
username: ${NACOS_DISCOVERY_SERVER_USERNAME}
password: ${NACOS_DISCOVERY_SERVER_PASSWORD}
config:
#服务配置,将会默认读取环境变量中的配置数据,如果不到数据,默认关闭
enabled: ${NACOS_CONFIG_ENABLE:false}
namespace: ${NACOS_CONFIG_NAMESPACE}
server-addr: ${NACOS_CONFIG_SERVERADDR}
group: ${NACOS_CONFIG_GROUP}
username: ${NACOS_CONFIG_SERVER_USERNAME}
password: ${NACOS_CONFIG_SERVER_PASSWORD}
3.中间件连接
中间件连接相关信息严格参考halo文档:http://halo.cd.zhinf.com/archives/zhong-jian-jian-fu-wu-fang-wen-yu-ming-ji-duan-kou-hao
需要注意的是内网环境nacos只有一个,tdengine、redis、mysql预演环境和测试开发环境是分开的。生产的服务统一通过 中间件.server来进行连接。
部署及更新
前端
打包
首先是打包,前端默认使用 nodejs16 版本进行打包,如需要其他版本打包,在项目根目录下面创建.env 文件,其中有两个变量:
NODEJS_VERSION:nodejs 版本号
BUILD_METHON:打包方法,默认为 npm,可以定义为pnpm或 yarn
前端统一通过 jenkins来进行打包,打包的镜像名为:harbor.zhxx.site/app/项目名_分支名,如果分支为 feature 或 main 则这里打包时会打成压缩包并传输至运维电脑上,手动上传更新部署。
例如环卫前端打包 test 分支,则镜像为:harbor.zhxx.site/app/zh-sanitation-frontend_test
生产打包:生产通过 jenkins 打包(或开发本地打包)将服务打包并传送至运维电脑,通过 ftp 手动上传更新部署
部署/更新
这里主要用 jenkins 进行部署更新即可,更新直接点击jenkins 任务运行即可。
1.如果是第一次部署,需要至少保证服务器:/app/frontend/conf/下面有 nginx 对应的配置文件,命名为:项目名.conf,例如环卫的配置文件为:/app/frontend/conf/zh-sanitation-frontend.conf。
2.确保 项目 nginx 配置文件里面的server_name字段后面跟的是项目访问域名,例如环卫:server_name zh-sanitation.test.zhxx.site; 这里zh-sanitation.test.zhxx.site 就是部署的域名,jenkins 构建后第一次部署会自动把这个域名配置于服务上。
3.修改了配置文件生效需要重启容器,可通过 rancher 重启容器。
生产环境部署更新:如果是生产服务器修改配置文件后需要在前端服务器上面通过nginx -s reload 来生效,更新或部署项目,将部署项目文件放置于/app/frontend/项目名即可,需提前将备份文件备份于:/app/frontend/backup 里面。
后端
打包
后端统一通过 jenkins来进行打包,打包的镜像名为:harbor.zhxx.site/app/项目名_分支名,如果分支为 feature 或 main 则这里打包时会将镜像的分支名命名为:prod
例如环卫后端打包 main 分支,则镜像为:harbor.zhxx.site/app/zh-urban-sanitation_prod
部署/更新
主要用 jenkins 进行部署更新即可,更新直接点击jenkins 任务运行即可。
测试及预演环境:如果是新项目第一次部署,可以通过/app/scripts/k3sDeploy.sh脚本来进行部署。如果是非新项目则可以直接通过 jenkins 构建来进行部署。k3sDeploy 脚本使用教程参考:http://git.cd.zhinf.com/omg/deployfiles
生产环境:生产环境目前除极个别服务以外,均为docker 部署。首先需要 jenkins 构建打包,打包完成以后进入项目路径,一般为:/app/backend/项目名 ,先执行:docker pull 镜像名(harbor.zhxx.site/app/项目名_prod)
,再执行:docker-compose down && docker-compose up -d 。下面是命令总结:
cd /app/backend/项目名
docker pull harbor.zhxx.site/app/项目名_prod
docker-compose down && docker-compose up -d
k3s/docker 管理服务
k3s管理服务
目前测试及预演均使用k3s 来作为容器运行管理服务,这里对常见命令以及故障排查处理做讲解。为了方便简单理解,这里可以把k3s 里面的 pod 当做 docker 里面的容器。
常见概念简述
· Deployment:用于管理 Pod 的生命周期,支持滚动更新、回滚、扩缩容
· Pod:实际运行应用的实例容器
· Service:为 Pod 提供统一访问入口(负载均衡)
日常运维管理中,大部分操作都是围绕 Deployment 和 Pod 进行。
k3s 常用管理命令
以下命令覆盖了 日常查看、更新、排查问题 的主要场景,是测试与预演环境中最常使用的一组命令。
查看类命令
# 查看节点状态:只要节点的STATUS 为Ready就表示节点正常(容器环境健康)
kubectl get nodes
# 查看命名空间:类似于 nacos 的 namespace,单环境无需关心这个,主要作用就是容器隔离
kubectl get ns
# 查看 Pod 列表
kubectl get pod:类似docker ps,查看所有容器
# 查看某个服务对应的 Pod
kubectl get pod -l app=<服务名>:查看指定的服务
# 实时查看 Pod 状态变化(发布时非常有用)
kubectl get pod -w
日志与排错
这里所有对pod的操作都需要知道pod名称,比如通过kubectl get pod 提前查看pod名称,然后对pod进行操作,pod命名命名规则为:服务名-随机字符串。也有一个办法可以操作,不用去查看pod 的名称,就是通过参数 l app=<服务名> 来替换pod名称。
# 查看 Pod 日志:查看 pod容器的日志,也可以通过 kubectl logs -l app=服务名
kubectl logs <pod-name>
# 持续查看日志(类似 tail -f):前台实时查看, 如果想要查看更多行的日志可以跟上--tail 100,这个命令和 docker logs 参数一样
kubectl logs -f <pod-name>
# 查看 Pod 详细信息(事件 / 启动失败原因):查看 pod 的详细信息
kubectl describe pod <pod-name>
经验建议:
· Pod 起不来:优先 describe pod,主要查看输出的events和Last State可以通过事件信息和上次挂掉的信息来判断问题
· 服务报错:优先 logs
Pod 操作
# 删除 Pod:删除了 pod 之后Deployment 会自动拉起新 Pod,相当于重新拉起一个容器,所以这里的删除可以理解为强制干掉容器并重启容器,如果需要真正删除容器需要删除其deployment:kubectl delete deployment 服务名
kubectl delete pod <pod-name>
# 进入 Pod 容器内部:进入容器虚拟机内部,有些小型容器没有 bash 命令则使用:kubectl exec -it <pod-name> -- /bin/sh
kubectl exec -it <pod-name> -- /bin/bash
删除 Pod 不等于删除服务,Deployment 会自动重新创建新的 Pod。
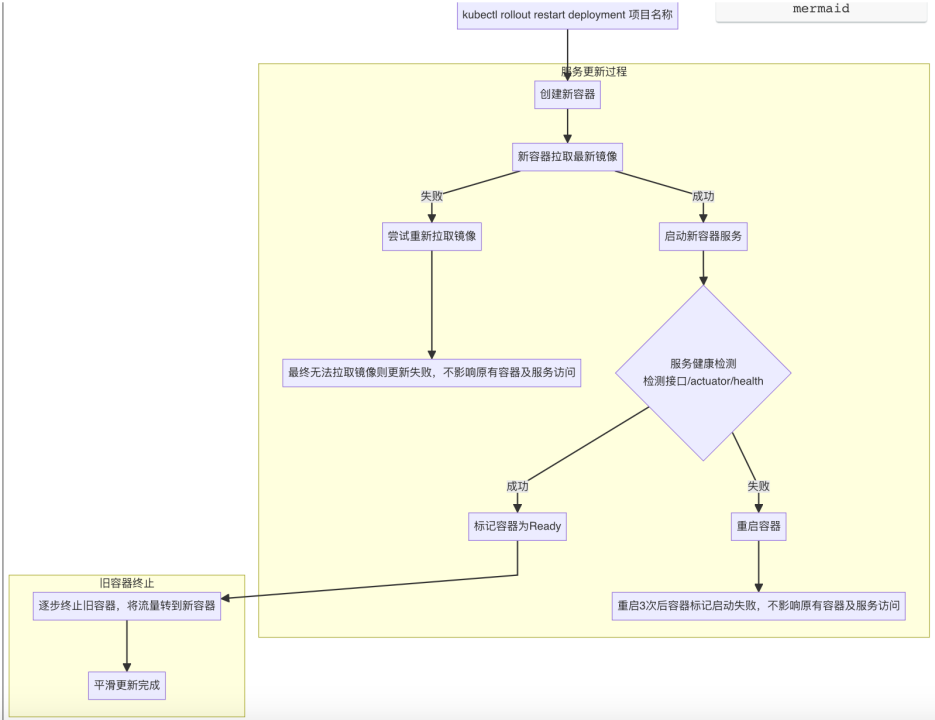
服务更新
kubectl rollout restart deployment 服务名 ,需要注意的是这里服务更新会在原容器不关闭的情况下新启动一个容器,例如下
root@test-server:/app/backend/budget-cservice# kubectl rollout restart deployment zh-urban-sanitation
deployment.apps/zh-urban-sanitation restarted
root@test-server:/app/backend/budget-cservice# kubectl get pod -l app=zh-urban-sanitation
NAME READY STATUS RESTARTS AGE
zh-urban-sanitation-554fc8c897-d8hn7 0/1 Running 0 2s
zh-urban-sanitation-74dcb79555-862nn 1/1 Running 0 8m37s
服务会启动一个新的容器,直至新容器启动完毕且/actuator/health接口正常时,老的容器才会被关掉。新框架下的服务更新,在服务更新完毕也就新服务器完全启动前,老服务不会停止关闭,不会影响前端用户访问使用系统。需要注意的是,如果更新的服务无法启动,就会一直存在两个容器,新服务会一直尝试启动。
问题排查方式
简单讲一下排查问题的方式。我把常见问题分为以下两大类:
1.所有服务异常
2.单个服务异常
所有服务异常
所有服务异常只有可能是以下几种原因:
1.服务所在服务器挂掉或者k3s 挂掉:
1.首先是ssh远程到服务器,如果服务器都无法远程则说明服务器未开机或以及处于异常状态。
2.如果服务器正常连接则通过以下两个命令检查k3s 服务是否存在异常
root@pre-server:/app/backend/zh-aiot# kubectl get node #这个命令显示status为 ready 即为正常
NAME STATUS ROLES AGE VERSION
pre-server Ready control-plane,master 39d v1.28.4-rc1+k3s1
root@pre-server:/app/backend/zh-aiot# systemctl status k3s #这个命令显示Active:active (running)则为正常
● k3s.service - Lightweight Kubernetes
Loaded: loaded (/etc/systemd/system/k3s.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2025-12-08 11:12:35 CST; 4 weeks 0 days ago
3.如果k3s 服务正常则使用kubectl get pod查看所有服务是否正常运行,以下面为例子,当服务的READY为 1/1 且 status为running 表示服务已正常运行,如果 status 为 running 但ready 为 0/1 则代表正在启动。
root@test-server:/app/scripts# kubectl get pod
NAME READY STATUS RESTARTS AGE
budget-cservice-589878fb59-w5tns 1/1 Running 0 29h
center-basic-auth-server-7d7fdbd7d7-vcsq5 1/1 Running 0 29h
center-basic-fulltext-search-server-78948f6864-ltpzq 1/1 Running 0 29h
2.中间件异常
在确认k3s都是正常的情况下,这个时候发现pod都处于0/1 running、0/1 error、0/1 CrashLoopBackOff 就表示服务器环境没问题,但容器无法正常启动,此时可以尝试kubectl logs -l app=服务名 查看一下容器日志,这种绝大部分情况都是中间件无法连接,如果确认问题,则需要对应处理排错中间件的运行是否存在问题。
单个服务异常
单个服务异常的排查思路通过kubectl get pod -l app=服务名 查看服务状态,通过状态来判断服务存在什么问题,如果只是单个服务存在异常,几乎可以排除中间件存在故障的情况。
下面列出常见的问题状态和排错说明:
docker 管理服务
生产环境以及部分内网环境主机目前仍以 Docker 作为主要的服务运行与管理方式,未直接使用 k3s。这里对docker 环境下的服务管理以及常见问题做讲解。
核心特点:
· 一个容器通常对应一个服务实例
· 服务是否可用,强依赖:
o 启动命令是否正确
o 前台进程是否持续运行
o 端口是否正确映射
· 不具备 自愈与滚动更新能力,不存在某个服务同时两个容器启动的状况
Docker 环境比较简单,因此,docker 环境下的问题,大多是 服务自身问题或启动方式问题,而非平台问题。
Docker 常用管理命令
docker 可以常见通过两种方式来管理,一是 docker 自带的命令,还有一种是通过docker-compose 命令来进行管理
容器查看
# 查看正在运行的容器
docker ps
# 查看所有容器(包含已停止)
docker ps -a
该命令主要注意以下状态:
容器是否存在
状态是否为 Running
启动时间是否异常频繁变化
日志查看(最重要)
# 查看容器日志
docker logs <container-id>
# 持续查看日志
docker logs -f <container-id>
在 Docker 环境中,80% 的问题都可以通过 logs 直接定位。
常见问题:
容器生命周期管理
# 停止容器
docker stop <container-id>
# 启动容器
docker start <container-id>
# 重启容器
docker restart <container-id>
# 删除容器
docker rm <container-id>
说明:
restart 本质是 stop + start
重启会导致服务短暂不可用
容器更新
Docker 环境下,服务更新通常遵循以下流程:
# 1.拉取容器镜像
docker pull 镜像地址
# 1. 停止旧容器
docker stop <container-id>
# 2. 删除旧容器
docker rm <container-id>
# 3. 启动新容器(或 docker-compose up -d)
docker run 启动参数 #如果是第一次部署只需要拉取镜像并运行
Docker-compose 常用管理命令
在实际docker环境中,所有服务都通过docker-compose命令来进行管理,与docker不同的是docker-compose命令需要在当前目录下存在docker-compose.yml文件,也就是项目部署文件,一般位于/app/backend/服务名/docker-compose.yml,服务的启动、停止、更新,原则上都通过 docker-compose 进行,以保证配置集中、行为可预期。
使用docker-compose 命令必须进入项目路径,如:cd /app/backend/zh-urban-sanitation
容器查看
# 查看当前 compose 项目下所有服务状态
docker-compose ps
关注:
服务是否为 Up
是否存在 Restarting / Exit 状态
容器生命周期管理
# 启动(或更新)所有服务
docker-compose up -d
# 停止并删除所有服务容器
docker-compose down
# 重启指定服务
docker-compose restart <service-name> #重启不会删除容器
# 停止指定服务
docker-compose stop <service-name> #停止不会删除容器
说明:
- up -d 会根据 docker-compose.yml 创建或更新容器
- down 只删除容器,不会删除镜像和挂载的数据目录
容器更新/部署
Docker Compose 的更新模式是 拉→停 → 起,不具备滚动更新能力。
标准更新流程:
# 1. 拉取新镜像
docker-compose pull <service-name> #有些服务器 docker-compose 会提示权限问题,则可以通过 docker pull 手动拉取镜像文件。
# 2. 重新创建并启动服务
docker-compose up -d <service-name>
使用 rancher 来管理服务
该部分取自halo文档:新架构运维文档
这里主要是展示解说一下rancher的使用,rancher本身是k3s的容器管理工具,可以理解为和之前的portainer一样
访问地址:https://rancher.zhxx.site/
访问并登录 rancher,在登录页面下面可切换为中文
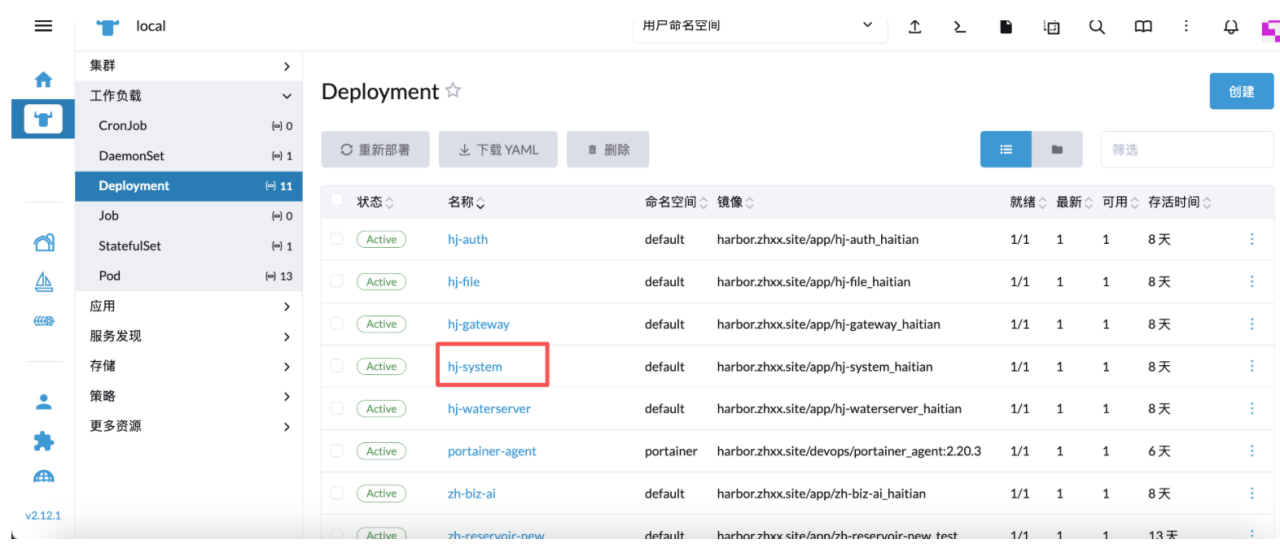
进入之后选择对应环境,默认是测试环境
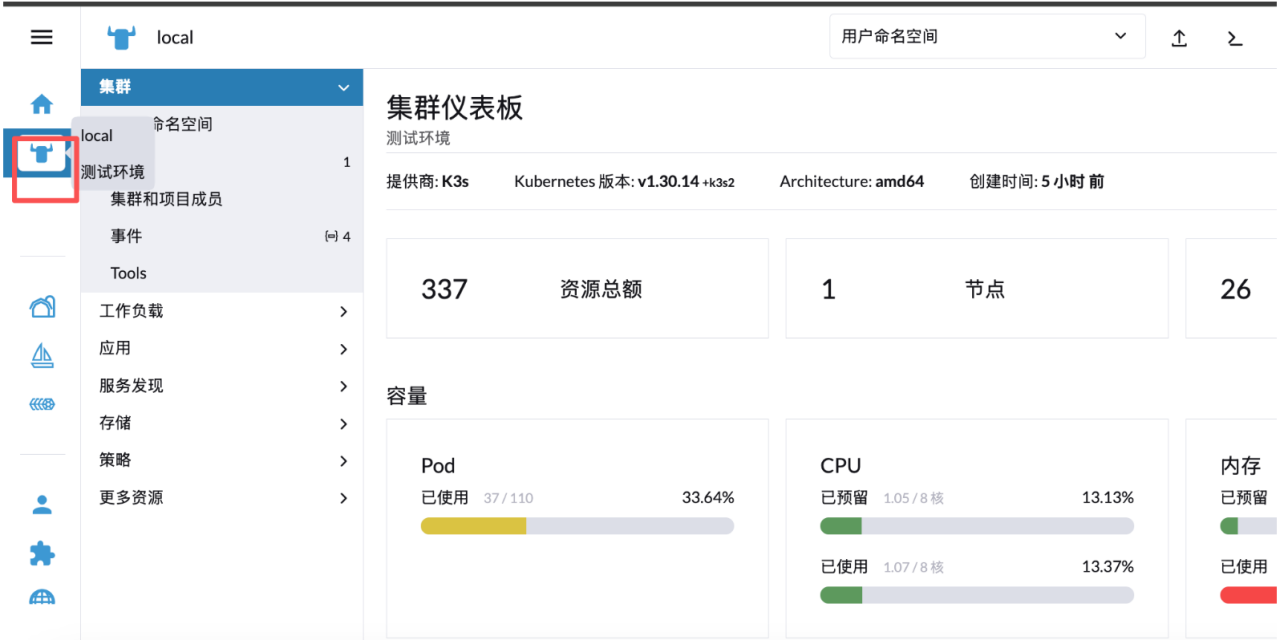
在工作负载的 deployment 下面可以看到所有部署的服务
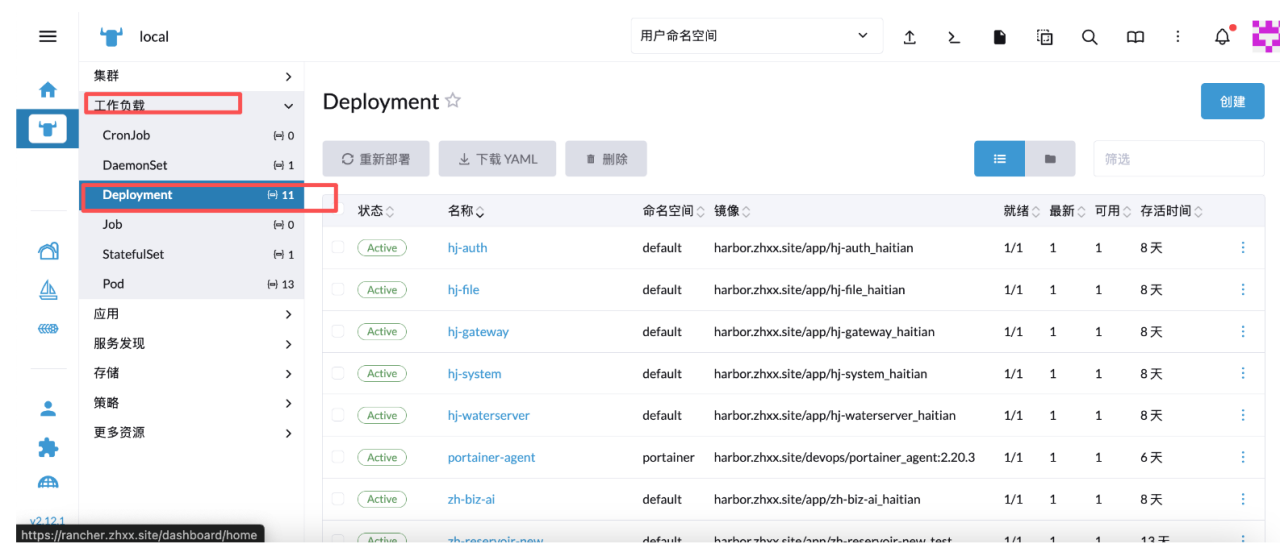
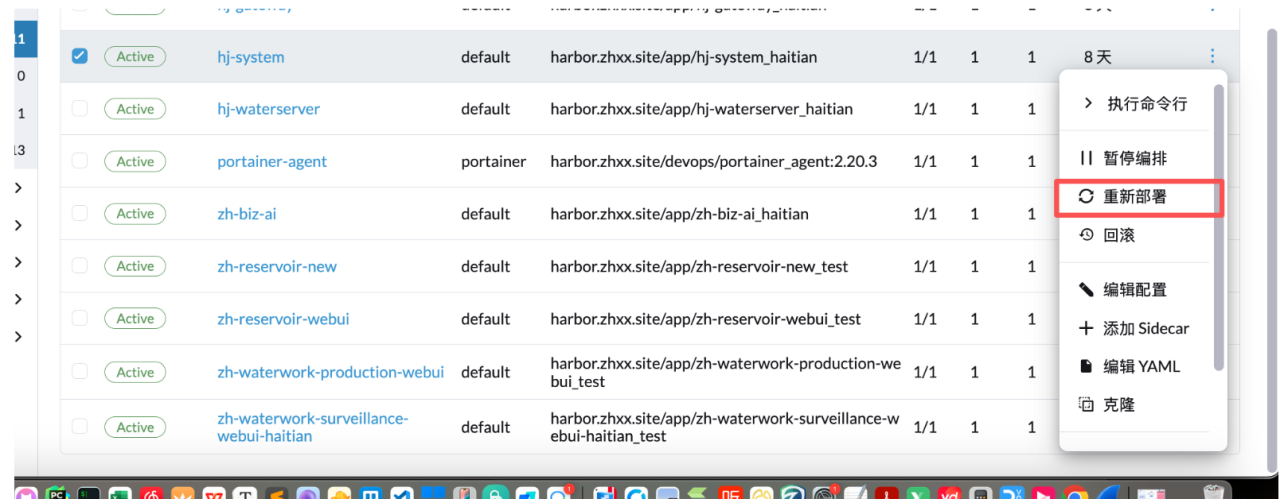
服务更新
选择服务最右边的三个点,编辑,然后点击重新部署
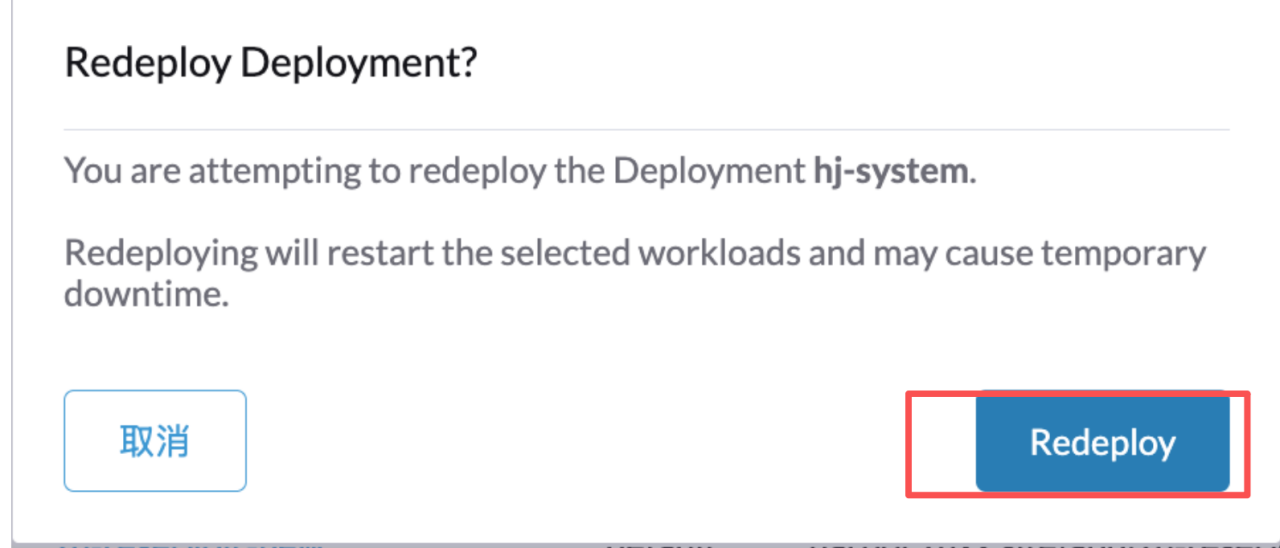
此时该服务的状态会变为In Progress,直至 active 才算更新完成
点击服务进去可以看到更新的时候同时运行的两个容器,一个是新容器,一个是老容器,目前更新都是平滑更新,只有新容器服务成功启动了才会停止老的
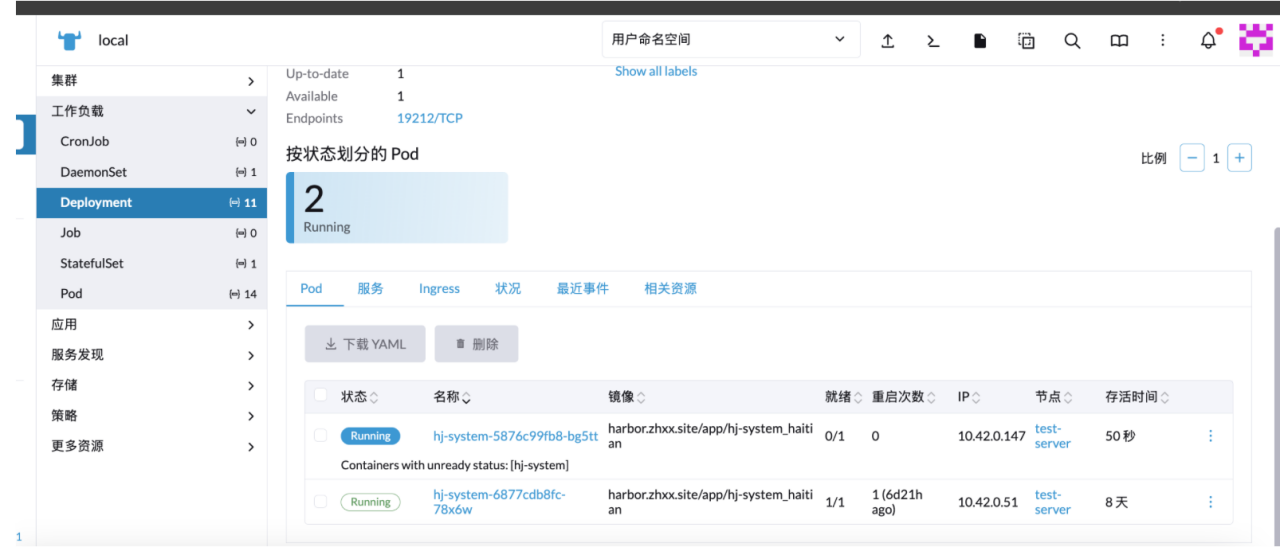
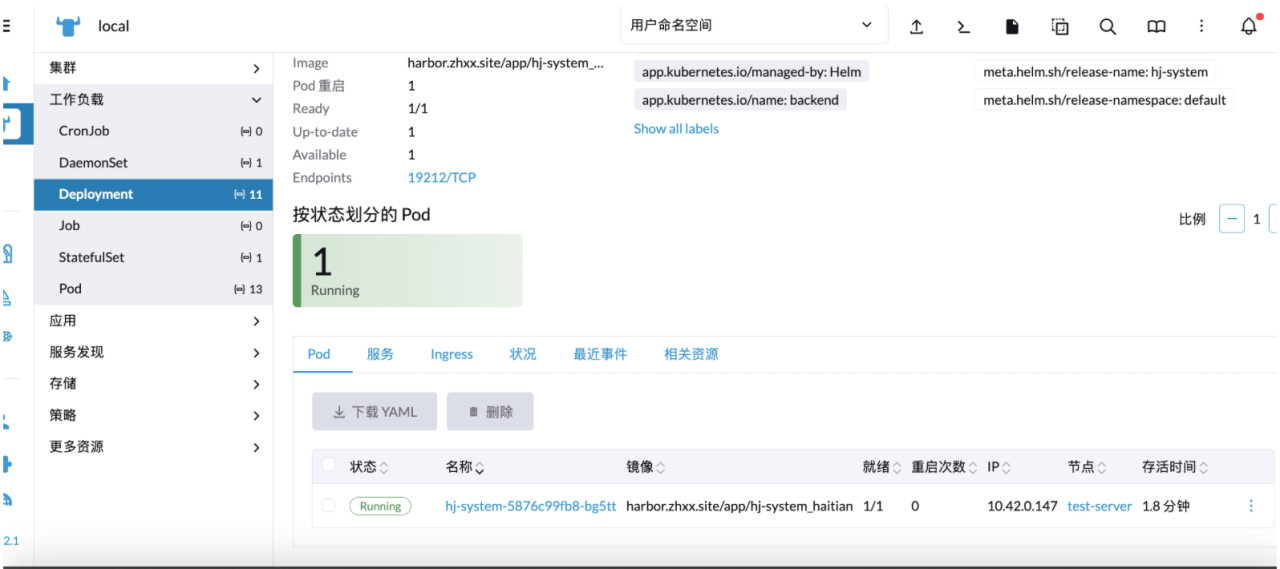
更新完成之后会关闭老容器,最终只有一个容器正在运行
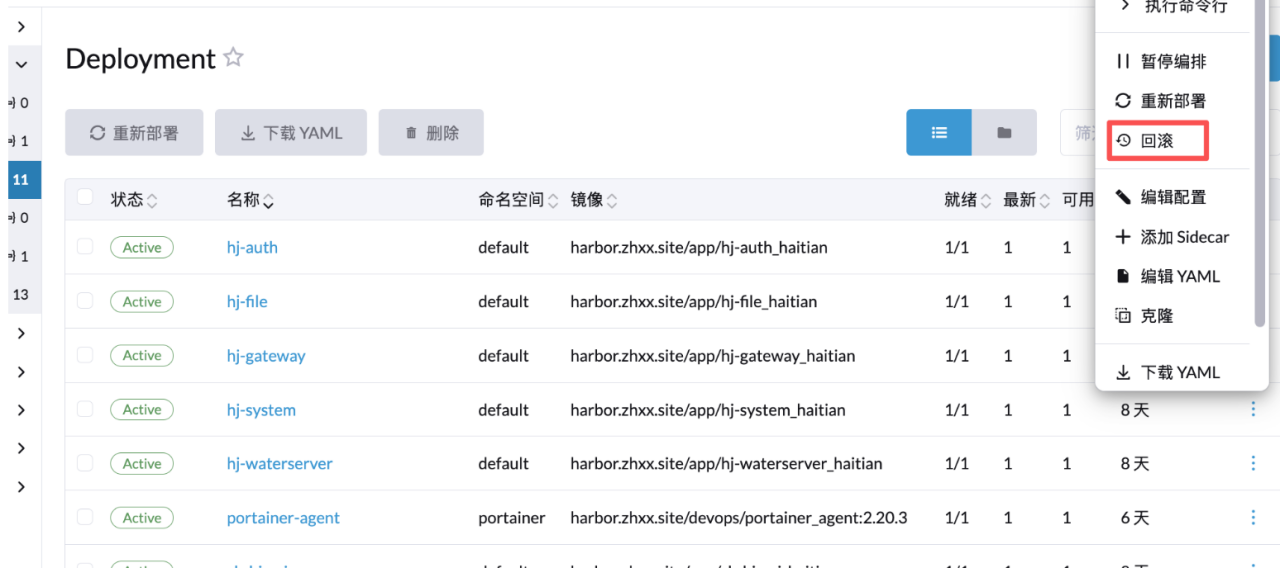
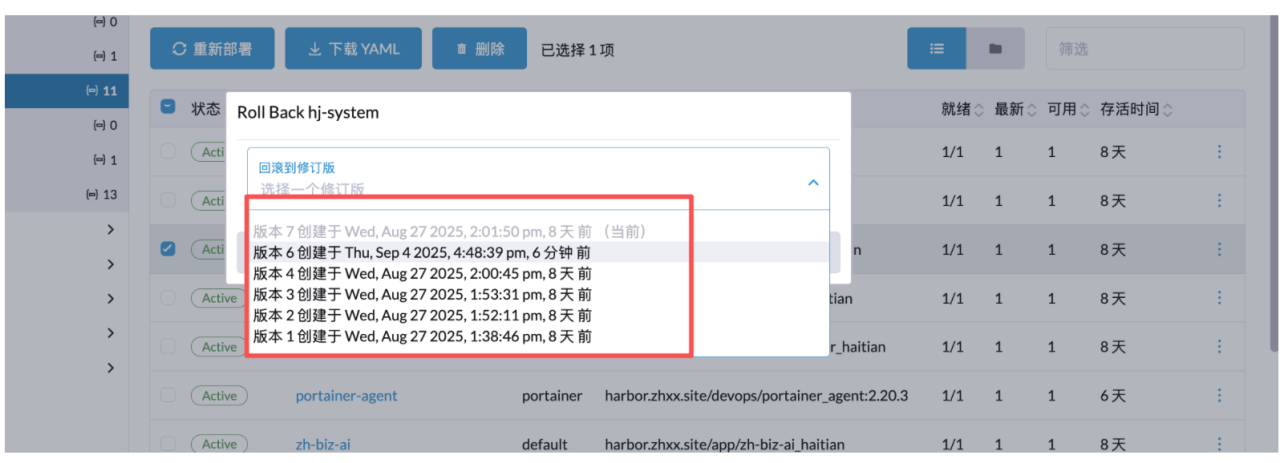
回滚
回滚基本上原理和更新一样,点击服务右边的三点,然后进入编辑,点击回滚
回滚需要选择版本,例如当前一共六个版本,版本 6 为当前版本,如需要回滚到上个版本,则选择版本 5.
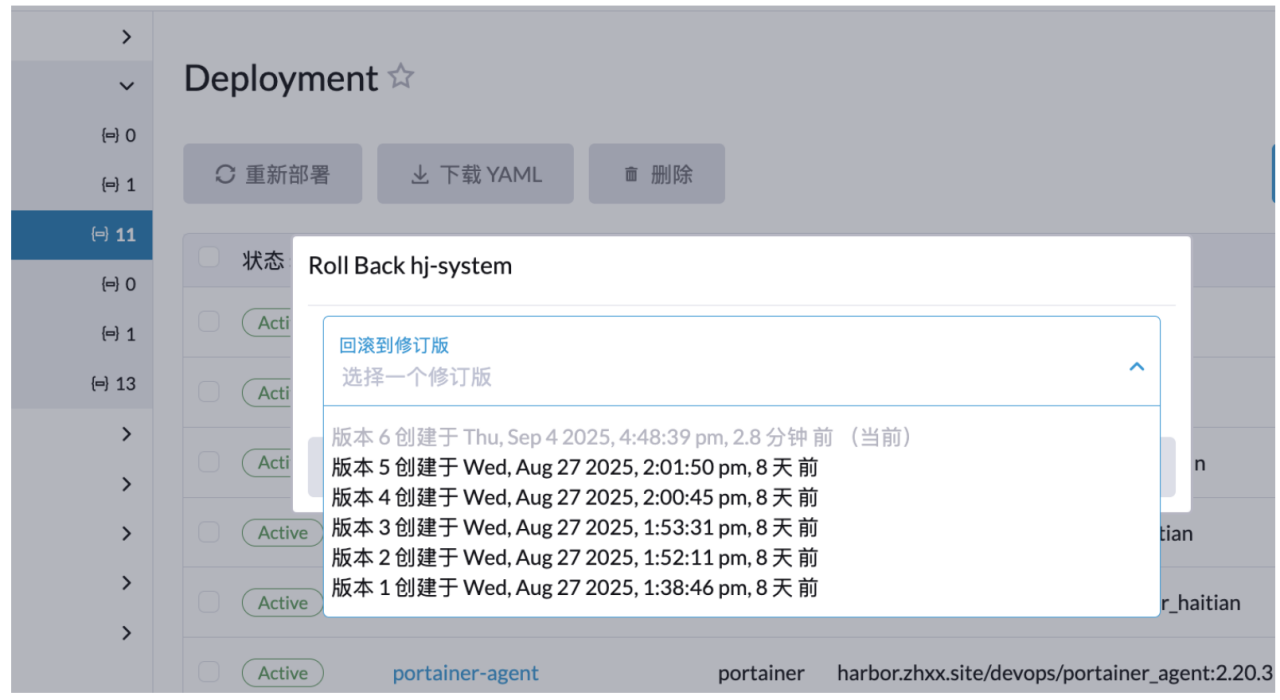
点击回滚以后服务进入In Progress 状态,和更新一样,直至上个版本的容器服务启动完成会停掉现有的容器,然后完成回滚操作。
回滚后再恢复到刚刚的版本
例如刚刚上面示例通过回滚,回滚到版本 5,这个时候回滚完成再打开回滚页面,会发现多了一个版本 7(当前版本),版本 5 不见了,因为当前版本 就是版本 5。如果想恢复到刚刚的版本,则选择版本 6 即可。
日志查看/进入容器
点击服务名
编辑查看日志
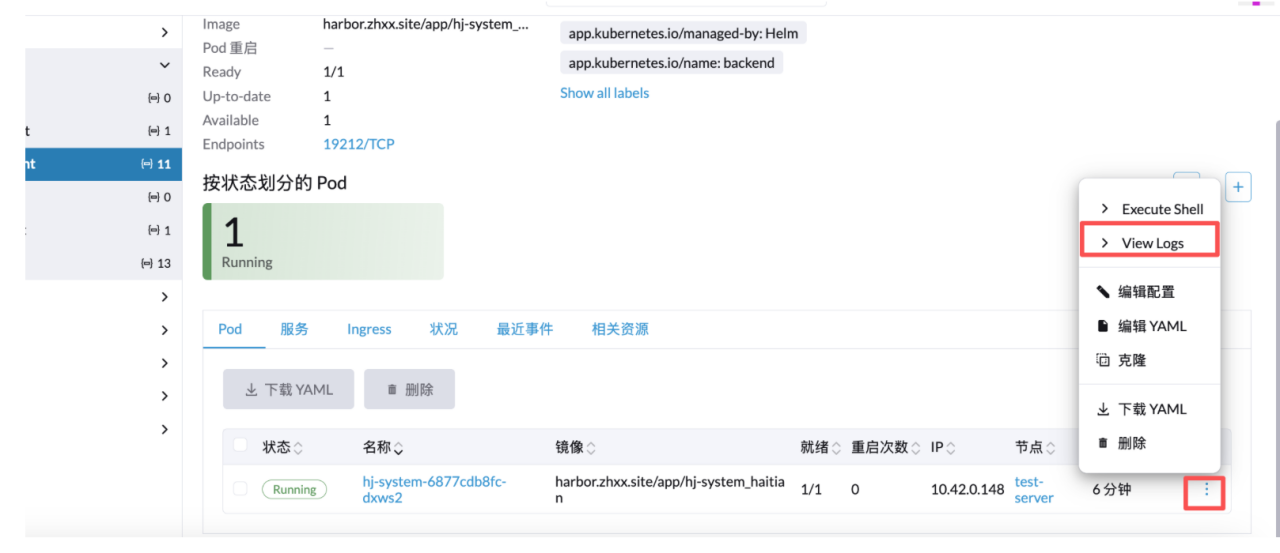
进入容器 shell 环境和日志一样,选择 execute shell 即可。
问题排错
这里排错和上面k3s 管理服务的排错一样,只是通过图形管理页面的方式对服务进行排错
所有服务异常
登录 rancher,在首页可以看到所有集群,通过其状态即可知道集群本身是否存在异常,如果现在 Active 则表示集群本身正常运行
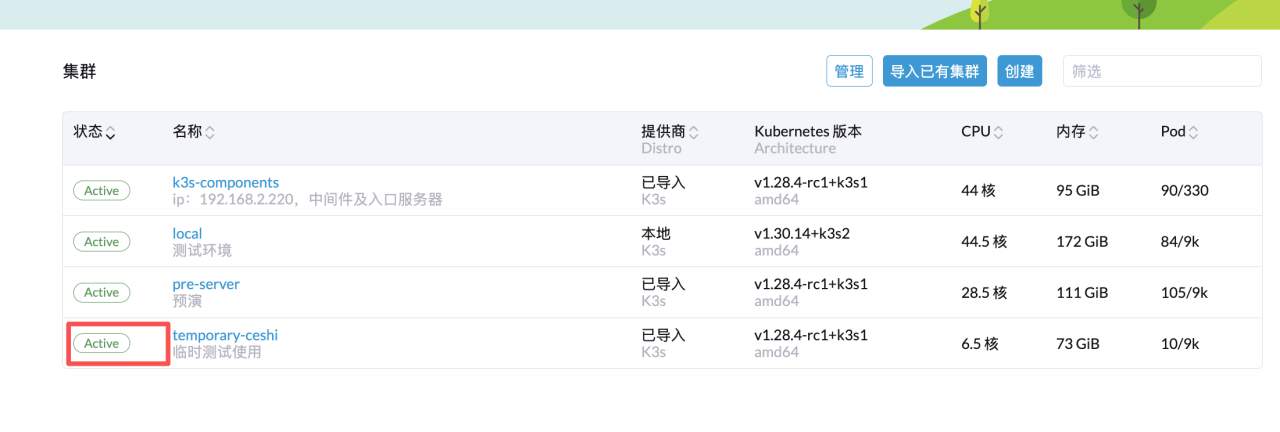
如果集群挂了则会显示 Unavailable,如下:
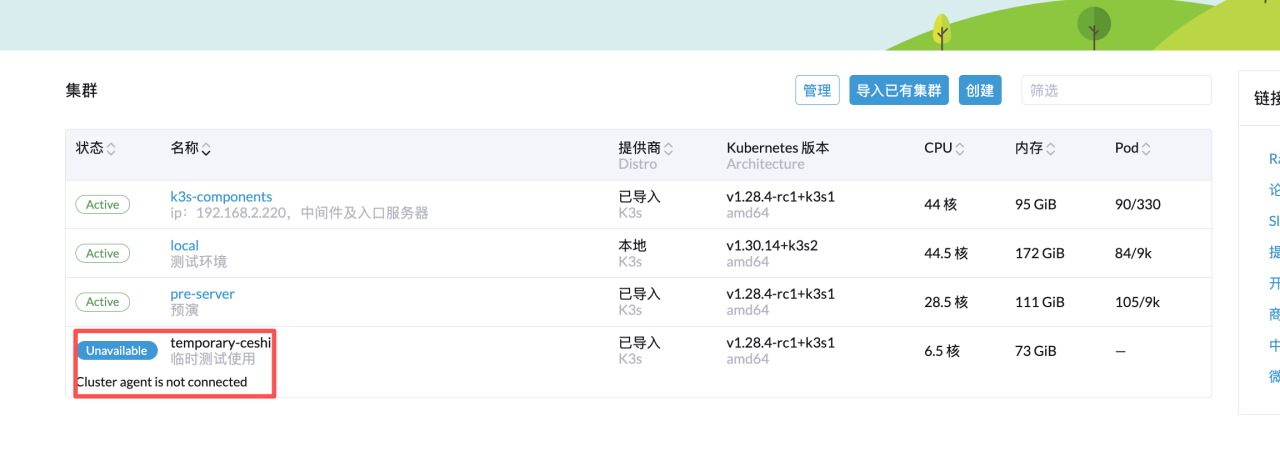
单个服务异常
进入集群,然后点击 pod,查看其状态,通过状态来判断服务故障问题即可,例如下:
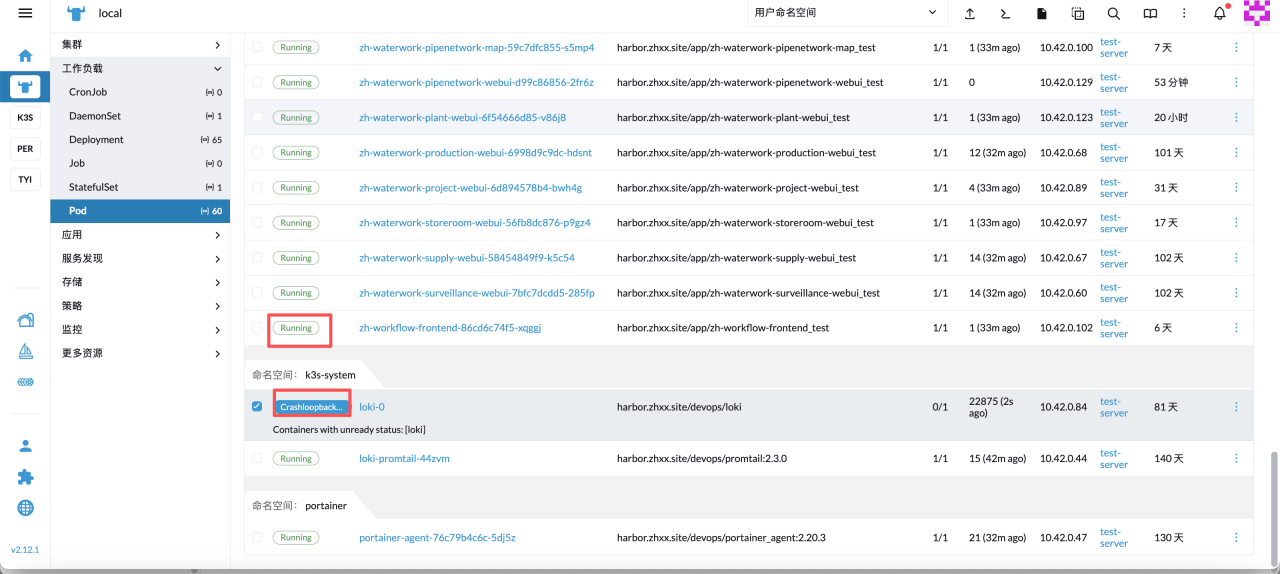
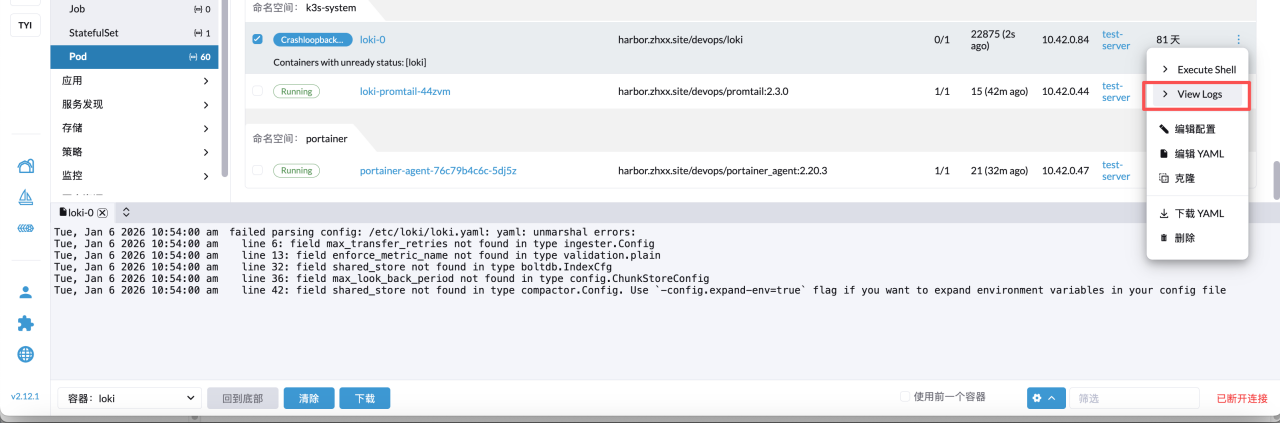
这里rancher 上面查看到该容器为Crashloopbackoff,则初步判断该容器已经启动,但多次启动失败了,所以这里直接通过查看日志排查即可:
loki
目前环境内查看日志只有两种方式:1.通过容器前台日志输出 2.通过 elk 来进行日志查看,第一种只能输出实时日志,当容器更新后日志会消失,第二种方式可以查看历史日志,但考虑到目前反馈 elk 并不好用,于是部署了一个新的 loki 服务来进行日志采集,并通过 grafana 来进行展示,目前测试预演已接入 loki 服务,开发人员先进行一段时间的使用,如果反馈比 elk 好用后续会应用到生产。
使用方法如下:
1.登录 grafana:https://grafana.zhxx.site/ 默认账号为: zhxx/zhxx@123456
2.登录以后选择Explore 然后选择 Loki(这里默认是 Loki)
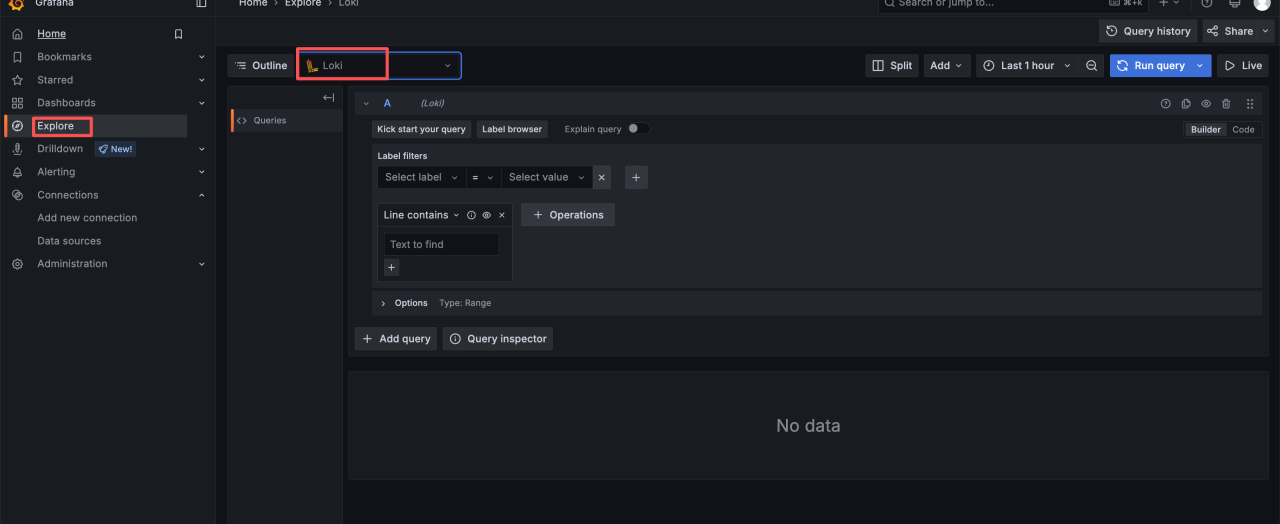
3.教程
如图常用的参数按钮如下
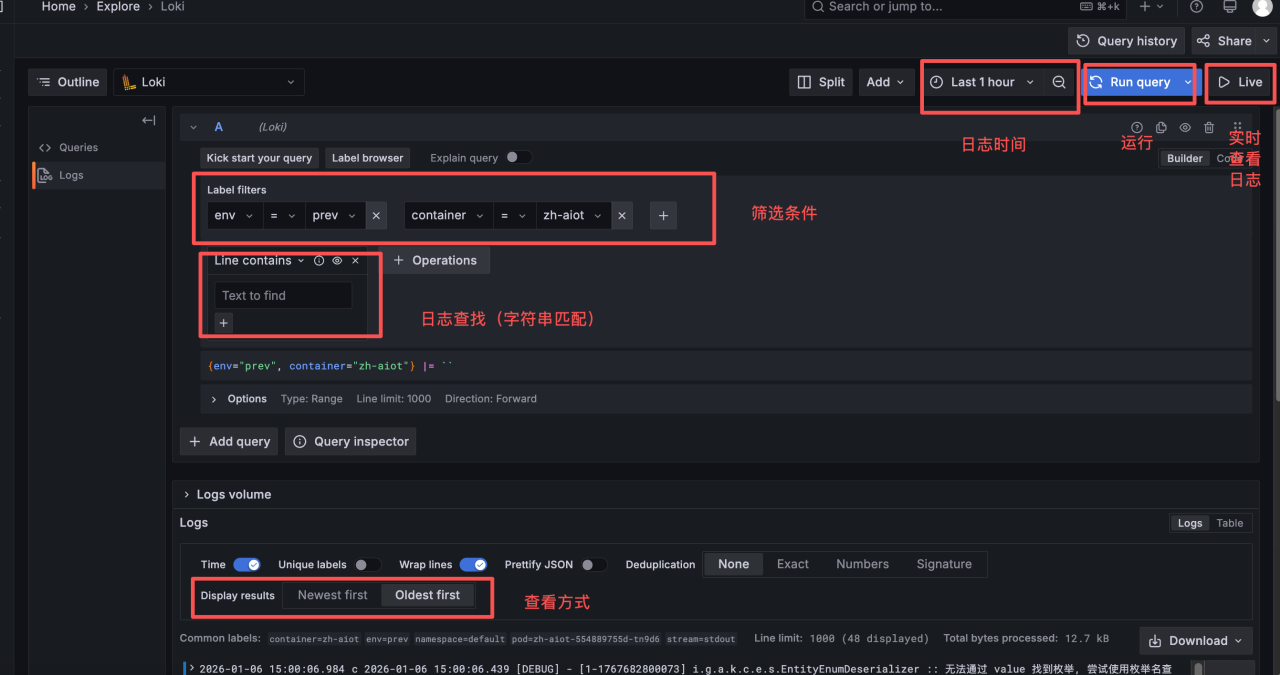
1.筛选条件:env对应环境,测试环境是 test、预演是 prev,以此类推
2.日志:主要是筛选日志,例如输入 error 则会筛选所有包含 error 的日志
3.查看方式:日志输出的方式,Newest first会从上到下输出先输出最新的日志,也就是时间倒序输出日志,elk 只能采用这种日志输出,也是大家觉得不好用的地方。还有一种是 Oldest first,这种输出方式会从上到下按时间正序输出。
4.日志时间:筛选查看日志的时间段
5.运行:筛选条件选完点击此按钮生效
6.实时查看日志:前台自动刷新,实时输出日志
效果如下:
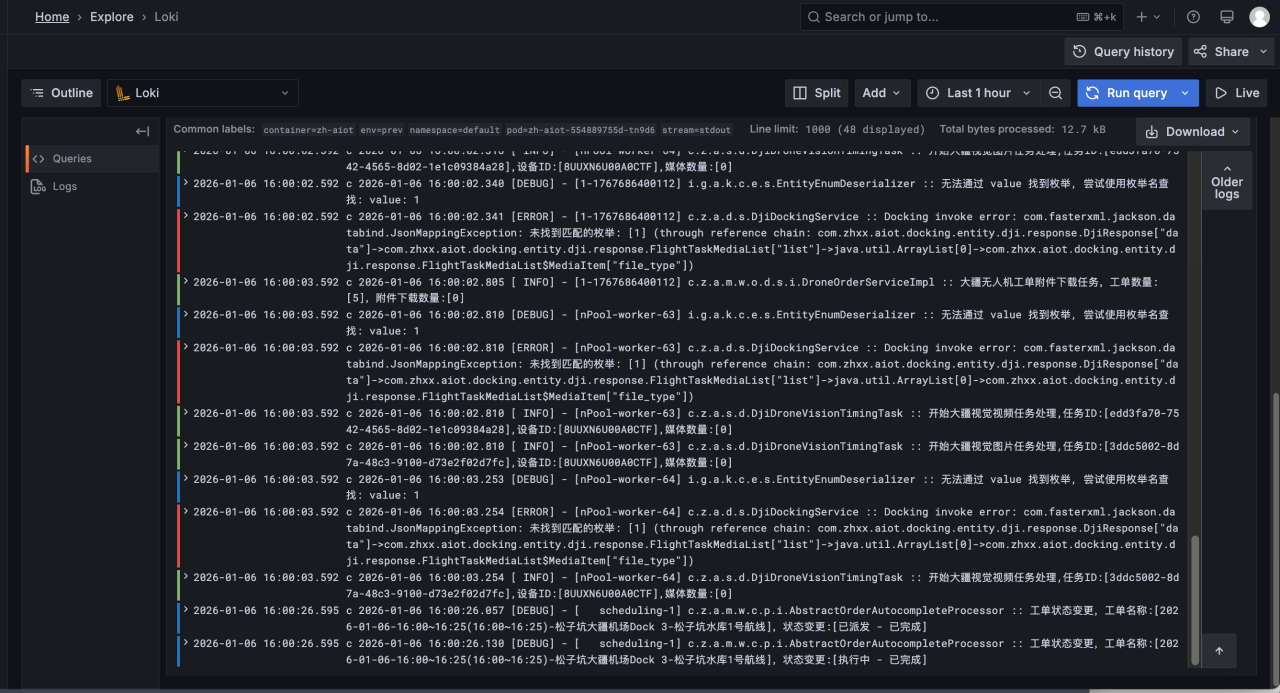
筛选日志: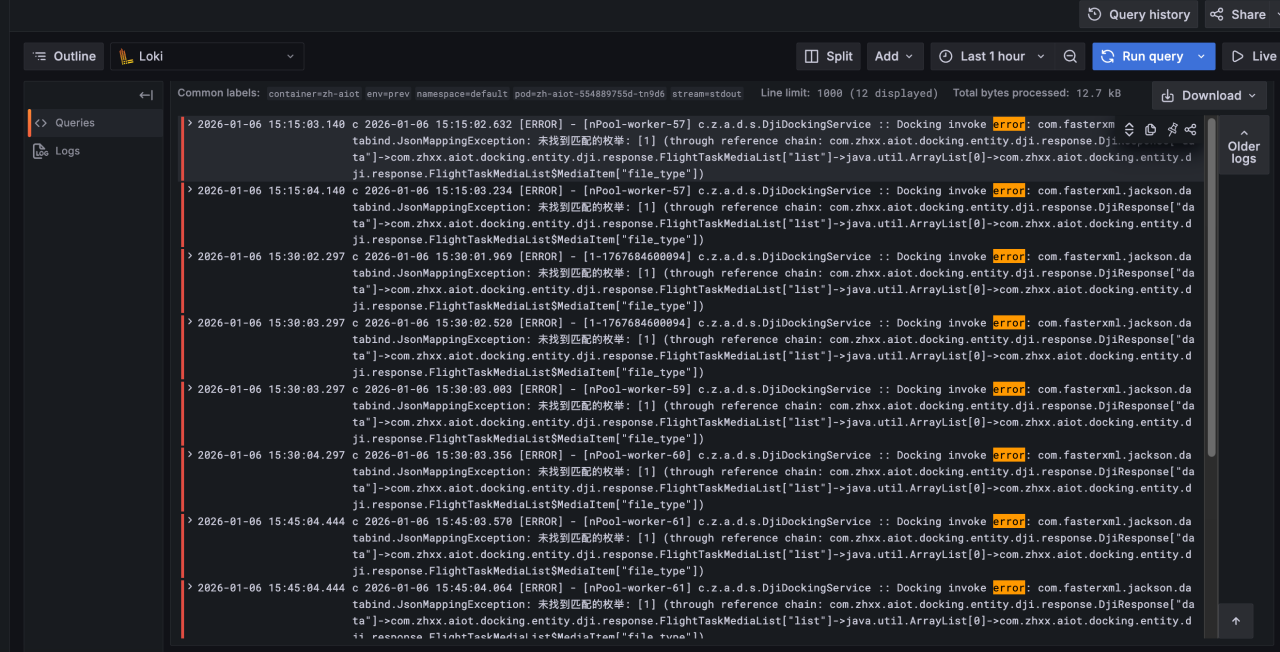
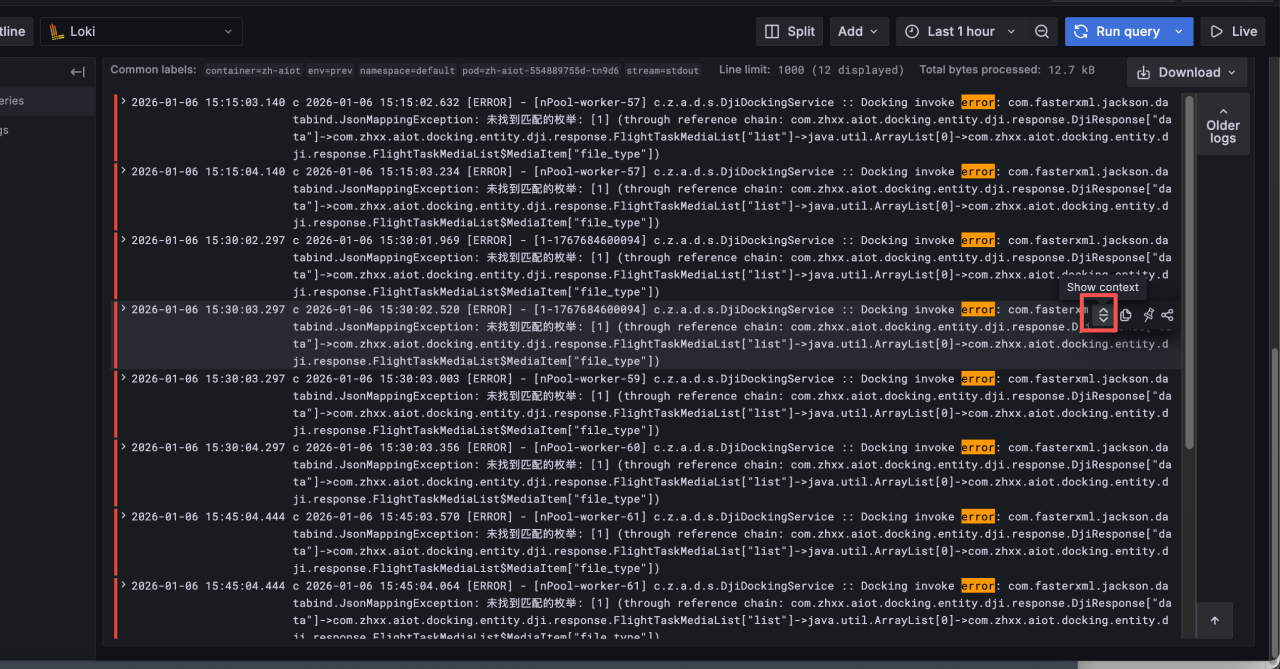
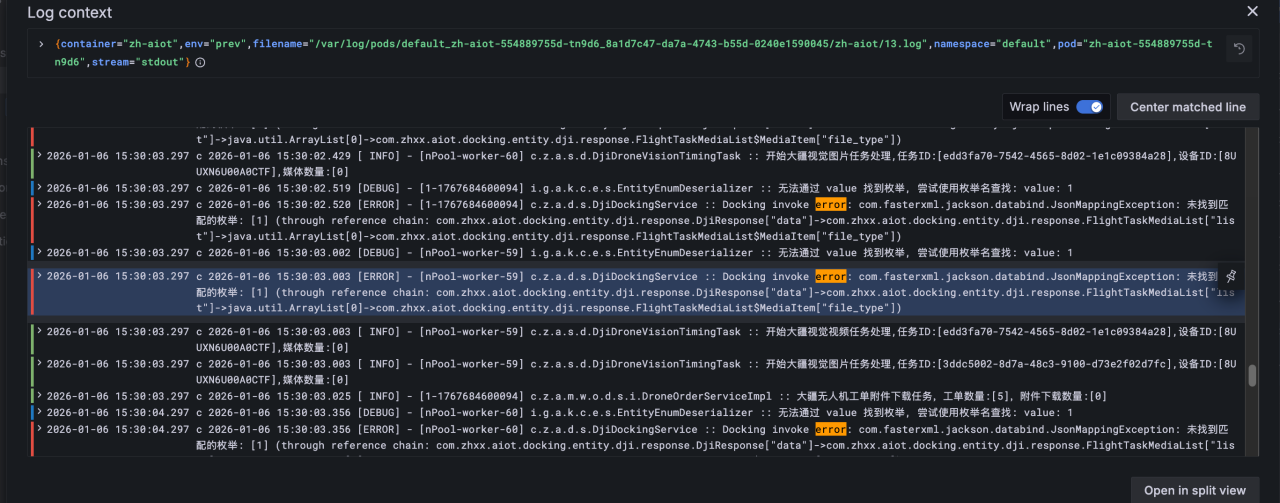
查看筛选日志的上下文
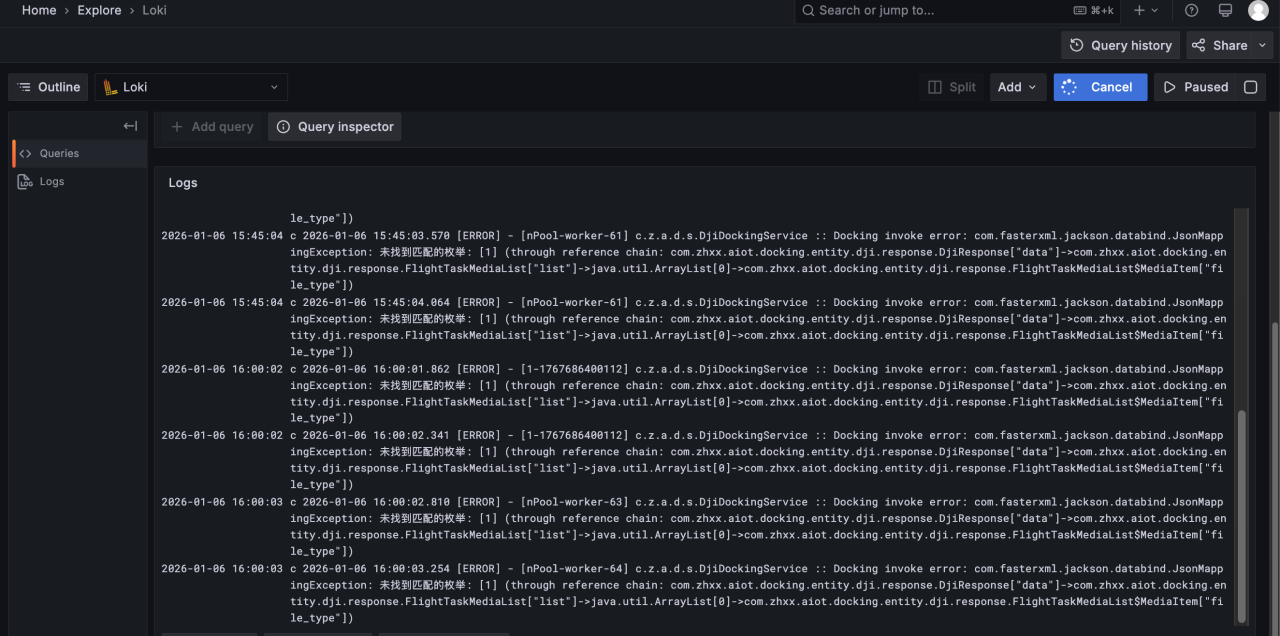
实时查看日志:
其他
服务排错(grafana)
关于环境内服务出现异常问题时,除了之前的问题排错,还可以通过 grafana 来判断服务是否有异常,grafana 本身已接入监控系统。
通过Alerting 下面的 Alert rules 可以查看到所有的监控告警,处于 normal 则表示正常状态。
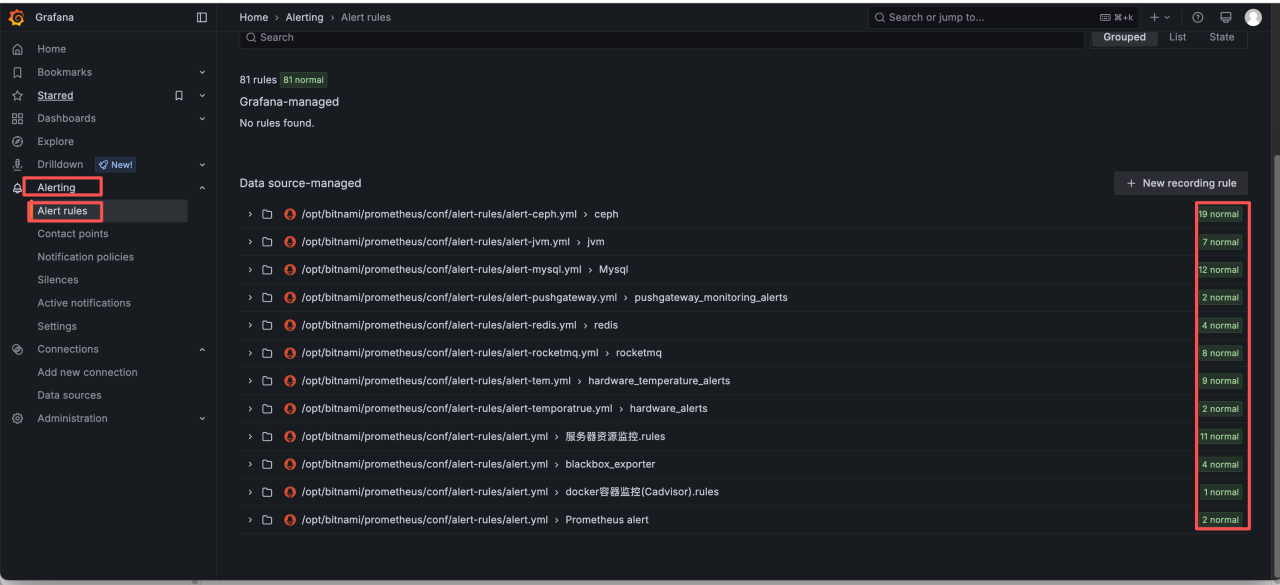
目前监控告警已经可以做到捕获环境内大部分异常,所以出现问题可以首先在 grafana 下面查看是否有异常告警,再针对性排查问题并处理。
如果有异常告警,会出现 firing
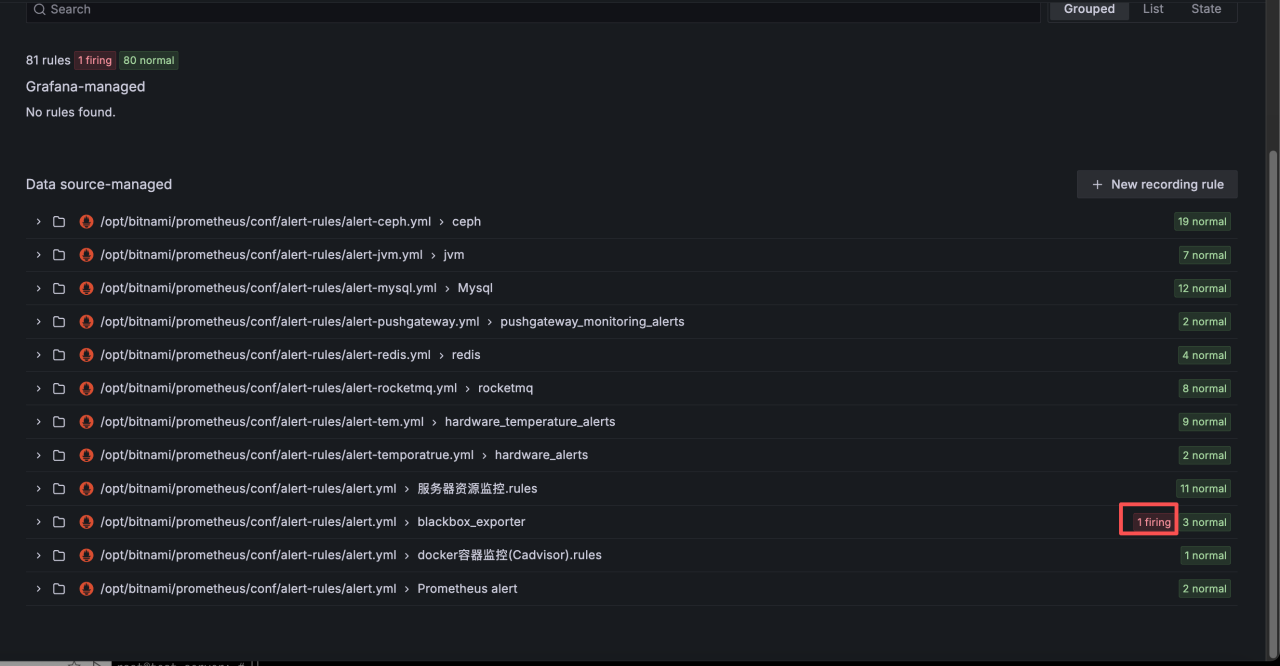
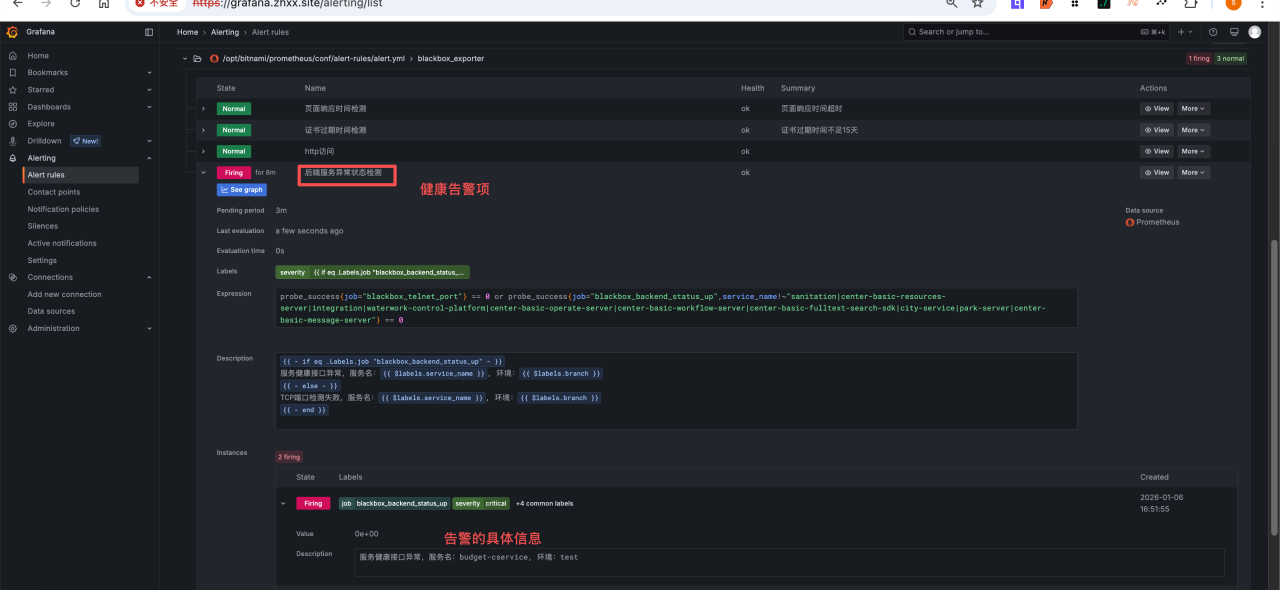
点开以后能看到监控项,再点开具体的告警项,就能看到告警信息。这样系统故障就一目了然。
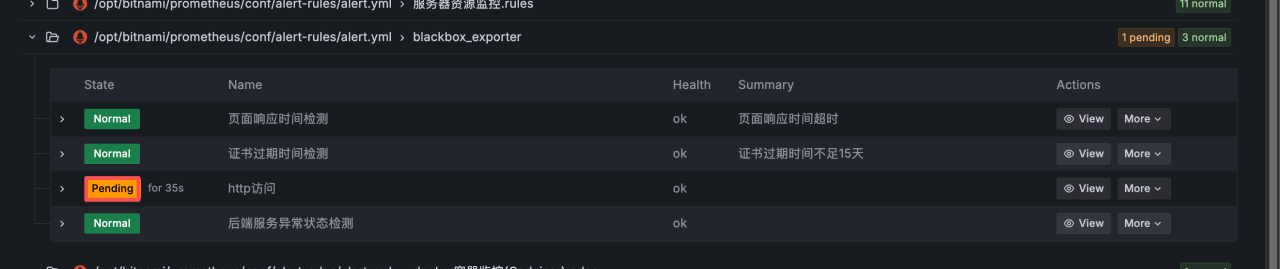
还有一种状态是 peeding,表示已经监测到异常,但未异常时间未达到设置的阈值。
新框架服务开启 debug 模式
进入 rancher,选择 deployment,编辑配置
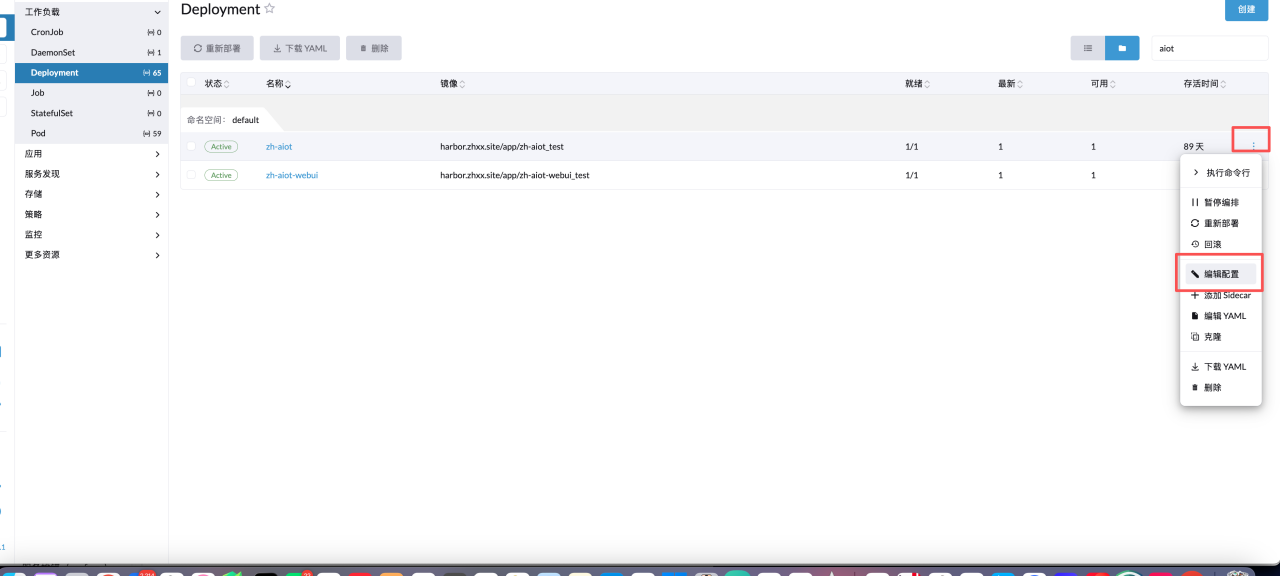
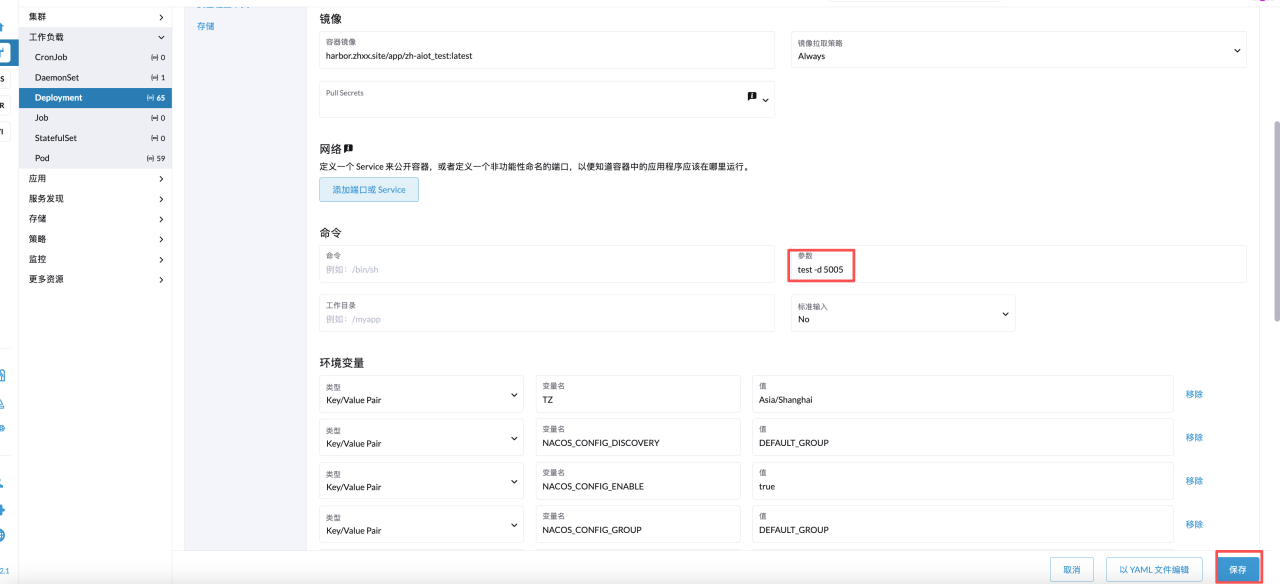
参数这里默认会跟上当前启动环境,在后面加一个-d 端口号,即可暴露 debug 端口,然后保存就行,例如: -d 5005
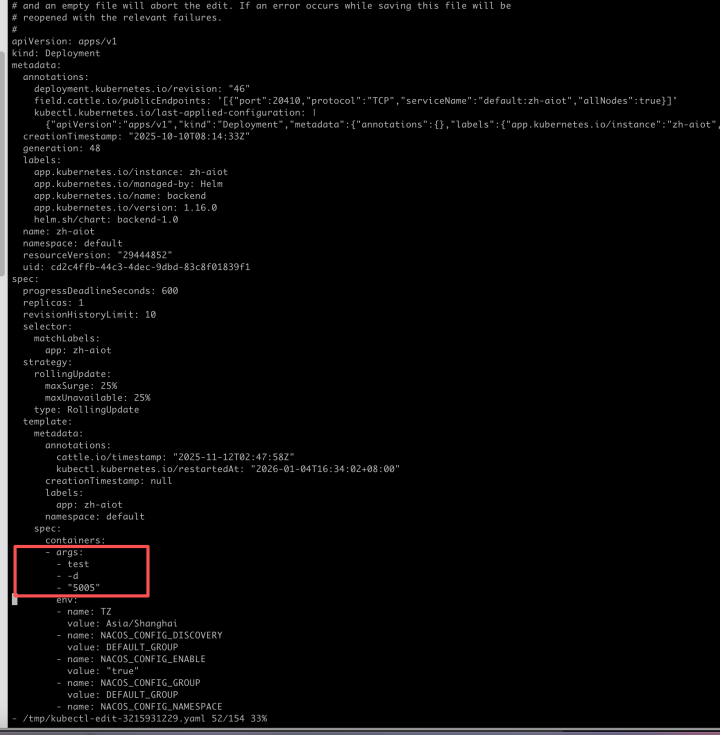
还有一种方式是通过命令行开始 debug,会麻烦一些,首先进入服务器然后执行命令:kubectl edit deployment 项目名,根据 yaml格式,在spec.spec.containers.args 下面跟上对应参数即可,最后通过键盘大写,按两下 Z 键即可保存生效。或者输入冒号:wq 也可以保存,需要注意的是这里的编辑是 vim 编辑方式,按i 进入编辑模式,按 esc 退出编辑模式。
后端服务文件管理
在测试和预演服务器分别有部署了一个filebrowser服务,分别为:http://filebrowser.test.zhxx.site,http://filebrowser.prev.zhxx.site/
1.这里简单讲解一下,首先所有后端服务都会挂载/app/data 目录,由宿主机的/app/backend/项目名/upload 目录挂载到每个项目的/app/data目录
所以这里当服务需要持久化存储的时候请将文件统一存储至/app/data
2.新框架服务在内存溢出的情况下也会将内存溢出的错误文件保存至/app/backend/项目名/upload 目录,通过 filebrowser 服务可以下载获取该文件